
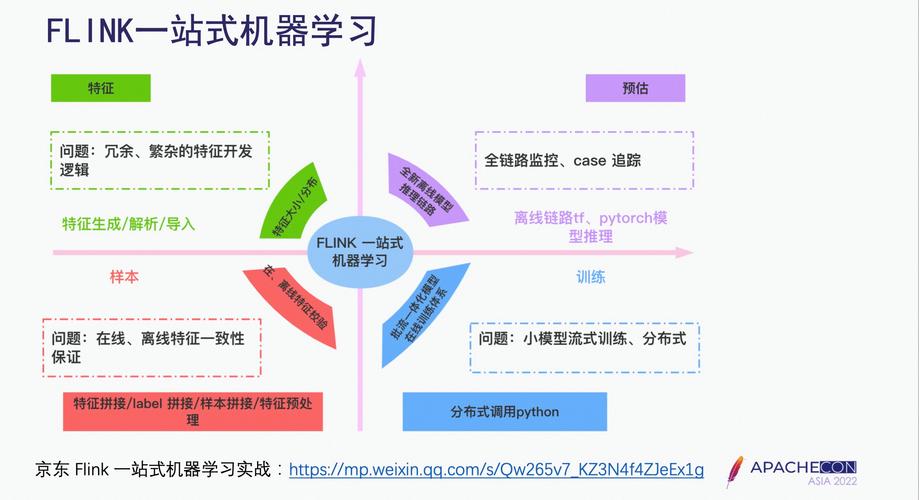
flink+机器学习_机器学习端到端场景

在当今大数据时代,实时数据处理和分析变得越来越重要,Apache Flink是一个高效、分布式、通用的数据处理引擎,它能够处理大规模数据流,并提供精确的时间控制和状态管理,结合机器学习算法,Flink可以应用于各种实时预测和分析场景中,下面将介绍一个端到端的Flink机器学习应用场景。
场景概述
设想一个电子商务公司想要实时地分析用户行为,以便提供个性化的产品推荐,并实时监控可能的欺诈行为,为了实现这一目标,公司决定使用Flink来处理实时数据流,并集成机器学习模型进行数据分析和预测。
系统架构
数据源
用户行为日志:包括用户点击、浏览、购买等行为。
交易数据:包括交易时间、金额、商品信息等。
数据处理流程
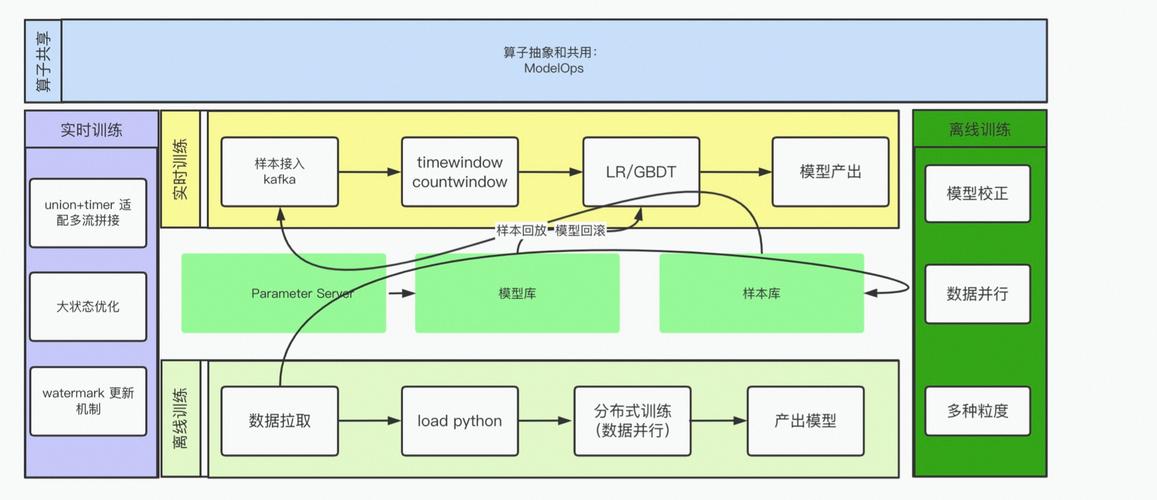
1、数据收集:使用Kafka作为消息队列,收集用户的实时行为数据和交易数据。
2、数据预处理:通过Flink对数据进行清洗、格式化、特征提取等操作。
3、特征工程:根据业务需求,构建适合机器学习模型的特征向量。
4、模型训练:利用历史数据离线训练机器学习模型(如随机森林、梯度提升树等)。
5、模型部署:将训练好的模型部署到Flink中,用于实时数据预测。
6、实时预测:Flink流处理程序调用部署的模型对实时数据进行评分和分类。
7、结果存储与反馈:将预测结果存储在数据库或数据仓库中,并根据业务反馈调整模型。
模型服务
推荐系统:根据用户实时行为,动态调整推荐列表。
欺诈检测:实时分析交易模式,识别异常行为以预防欺诈。
技术细节
Flink作业示例
假设我们使用Flink SQL来编写处理用户点击数据的作业:
创建源表,连接到Kafka主题
CREATE TABLE user_clicks (
user_id INT,
item_id INT,
timestamp TIMESTAMP(3),
event_type STRING
) WITH (
'connector' = 'kafka',
'topic' = 'user_clicks',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json'
);
创建汇表,将预测结果写入新Kafka主题
CREATE TABLE click_predictions (
user_id INT,
predicted_event STRING
) WITH (
'connector' = 'kafka',
'topic' = 'click_predictions',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json'
);
插入Flink作业逻辑
INSERT INTO click_predictions
SELECT
user_id,
CASE
WHEN event_type = 'click' AND model_score(item_id) > 0.5 THEN 'likely_to_purchase'
ELSE 'not_likely_to_purchase'
END AS predicted_event
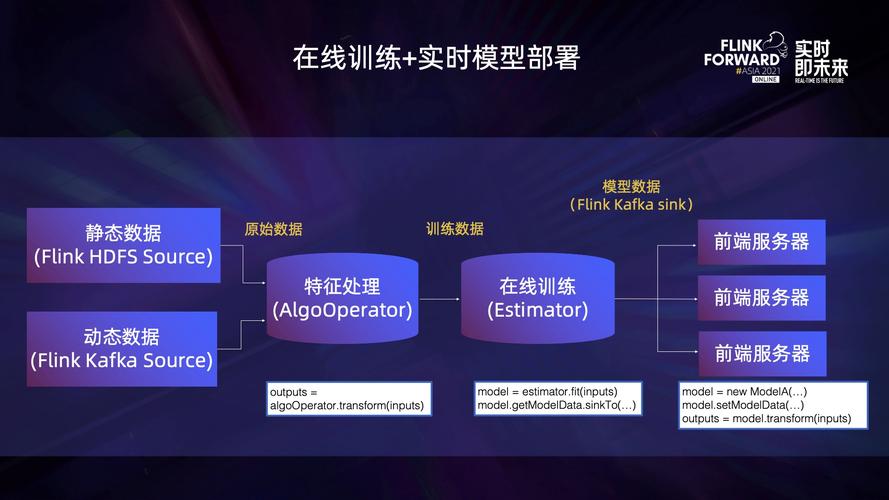
FROM user_clicks; 模型服务化
可以使用Flink的机器学习库或将训练好的模型导出为PMML或其他格式,然后在Flink作业中调用。
挑战与优化
数据质量:确保输入数据的质量,处理缺失值和异常值。
特征工程:设计合适的特征,提高模型预测的准确性。
模型更新:定期更新模型以适应数据的变化。
延迟优化:优化Flink作业以减少端到端延迟,满足实时性要求。
通过上述架构,我们可以实现一个端到端的实时机器学习系统,该系统能够即时处理和响应大规模数据流,这种系统尤其适用于需要快速反应的应用场景,如个性化推荐、欺诈检测等。
相关问题与解答
Q1: Flink如何保证实时机器学习任务的低延迟?
A1: Flink通过以下方式保证低延迟:
流处理:不同于批处理,Flink的流处理模型允许它能够在数据到达时立即处理。
内存计算:Flink主要在内存中处理数据,减少了磁盘I/O的开销。
窗口和水印机制:Flink提供了灵活的窗口操作和水印支持,以处理乱序数据流并及时产出结果。
反压机制:Flink有内置的反压监测和处理机制,可以动态调整任务的并行度以避免处理瓶颈。
Q2: 如何在Flink中部署和使用外部机器学习模型?
A2: 在Flink中部署和使用外部机器学习模型可以通过以下步骤实现:
模型导出:首先需要将训练好的模型导出到一个适合的格式,例如PMML或ONNX。
模型集成:在Flink作业中集成模型,可以通过自定义函数或者使用Flink提供的机器学习库来完成。
调用模型:在Flink作业的逻辑中添加调用模型的代码,对流经的数据进行实时评分或分类。
模型服务化:也可以将模型部署为REST API服务,并在Flink作业中通过网络请求来调用模型。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复