
分布式关系型数据库是现代数据库管理系统中的一个重要组成部分,它结合了分布式系统与关系型数据库的特点,旨在处理大规模分布式数据,本附录致力于详尽地解释分布式关系型数据库的相关概念、特点、以及在实际场景中的应用情况,具体如下:
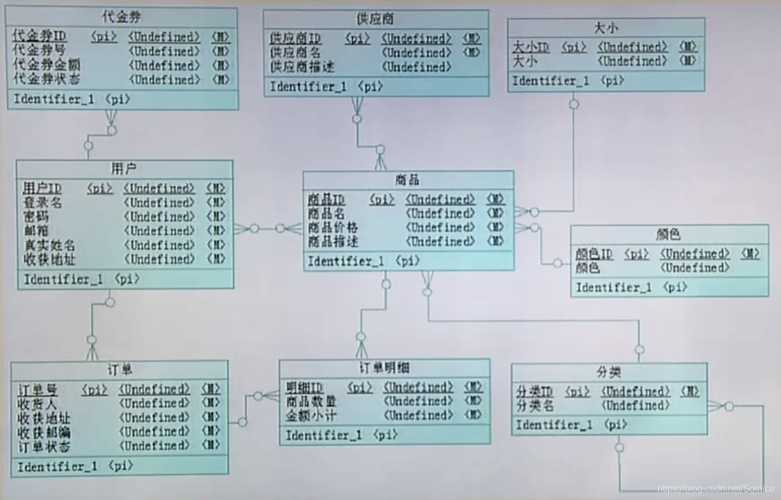

1、定义与基本概念:
分布式关系型数据库通常由多个物理分布的数据库节点组成,这些节点协作处理数据存储和查询请求,每个节点都可以独立处理请求,同时也能与其他节点协作完成复杂的任务。
分布式关系型数据库保持了传统关系型数据库的核心特征,例如支持SQL查询语言,以及表之间维持关系完整性。
2、主要特性:
分布式关系型数据库能够在多个服务器节点之间分散数据和负载,从而提升整体的处理能力和容错能力,如此设计,可以在不牺牲关系型数据库核心优势的前提下,实现数据的横向扩展。
分布式关系型数据库通过复制和分区技术,提高了数据的可靠性和可用性,即使部分节点失效,系统仍可正常运作。
此类数据库支持透明的水平扩展,即用户无需修改应用即可实现数据库的扩展,这为处理大规模数据提供了极大的便利。
3、分布式关系型数据库的架构:
这类数据库通常包含一个或多个主节点和多个从节点,主节点负责协调请求和数据分发,而从节点则直接处理客户端的请求。
数据在各个节点间按照一定的分配策略进行存储,常见的策略有范围分区、散列分区等。
4、技术实现:
如Citus扩展,为PostgreSQL数据库添加了数据分发和事务处理的能力,使其能够更好地在分布式环境中工作。
分布式关系型数据库需要在节点间进行数据同步和一致,这要求高效的网络通信机制和先进的同步技术。
5、应用场景:
高并发的联机交易处理(OLTP)是分布式关系型数据库的常见应用场景,特别适用于金融等行业的大规模数据处理需求。
这些数据库可以进行弹性伸缩,非常适合云环境和大数据处理的需求。
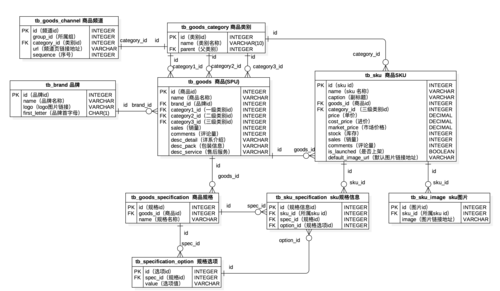
在选择分布式关系型数据库时,以下几点值得注意:
考虑数据一致性需求与业务场景的匹配程度。
评估数据库的扩展能力是否满足未来的增长预期。
分析不同产品的性能指标,选择性价比最优的解决方案。
分布式关系型数据库以其独特的优势,如高度的可扩展性、高可用性和强大的故障恢复能力,正在成为处理大规模分布式数据的首选技术,了解其工作原理和适用场景,可以帮助企业和开发者更有效地设计和实施数据存储解决方案。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复