
在现代数据库管理系统中,分布式数据库和关系型数据库(RDS)各自扮演着重要的角色,它们不仅在数据存储方式、数据一致性以及可扩展性等方面存在差异,还在很多服务领域有着独特的联系和配合方式,具体分析如下:

1、数据存储方式
关系型数据库:通常配置在单个物理节点上,所有数据集中存储管理,具有固定的表结构,强化完整性约束,支持复杂的查询和事务处理能力,适合需求高一致性的业务场景。
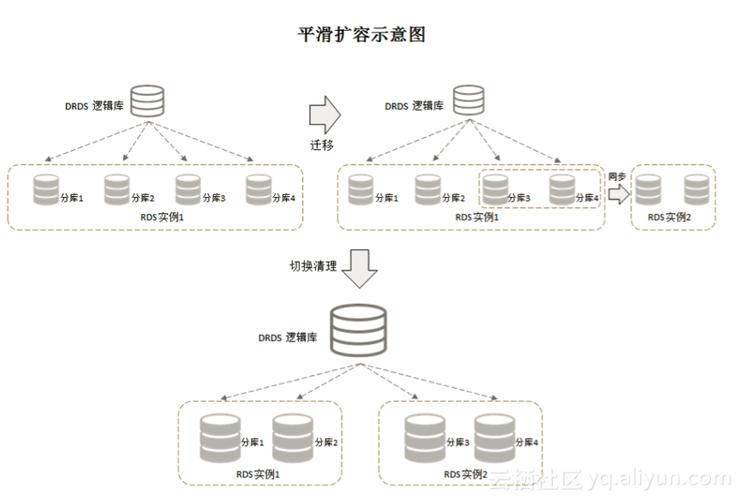
分布式数据库:将数据分散存储在多个物理节点上,提高了数据的可用性和可扩展性,缺乏关联性,更加灵活,支持动态增减节点,适应于大规模数据处理和高并发访问的应用环境。
2、数据一致性
关系型数据库:强调ACID事务特性,保证了操作的原子性、一致性、隔离性和持久性,为数据提供了强有力的可靠性保证。
分布式数据库:多采用BASE原则,强调系统的可用性与性能,对强一致性要求相对较低,适合读写并发高且容忍一定延时的场景。
3、可扩展性
关系型数据库:由于其集中式架构,垂直扩展(如升级服务器配置)相对容易,但水平扩展(增加更多节点)会面临较大挑战,受限于单节点资源。
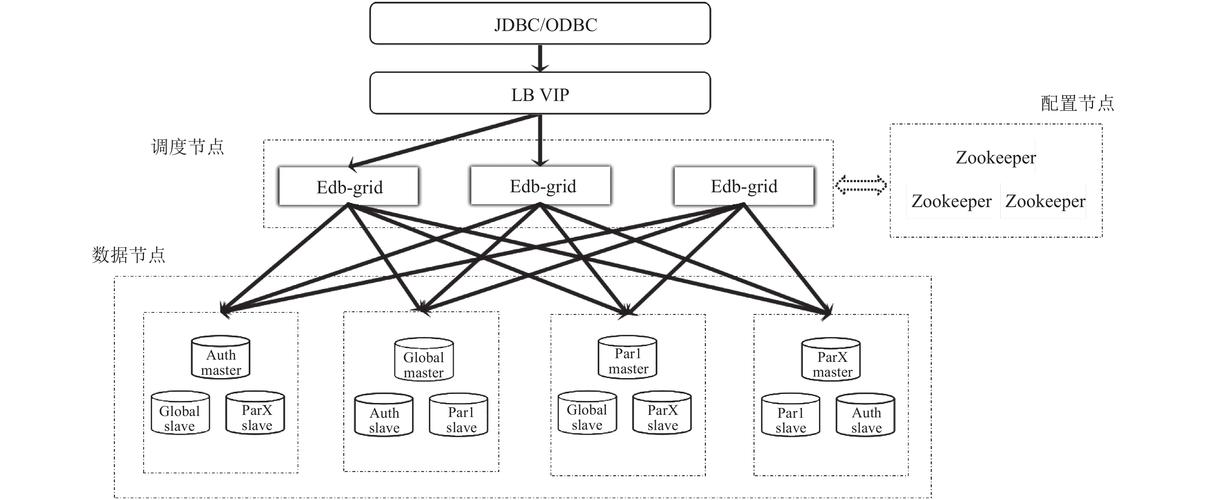
分布式数据库:设计之初就考虑到可扩展性问题,通过增加节点数量轻松实现系统的横向扩展,满足不断增长的业务需求。
4、适用场景
关系型数据库:适合业务逻辑复杂、数据间关系密切、需要严格事务管理的应用场景,如金融、信息系统等。
分布式数据库:更适用于需要处理海量数据、高并发访问、及对扩展性有较高要求的互联网服务和应用,例如大数据处理、实时分析等。
5、查询语言
关系型数据库:支持SQL等成熟的查询语言,便于进行复杂查询和操作,并有利于维护与开发效率。
分布式数据库:查询方式更为灵活,但可能不支持复杂的SQL查询,更多依赖于非结构化的查询语言或API调用。
6、独立性
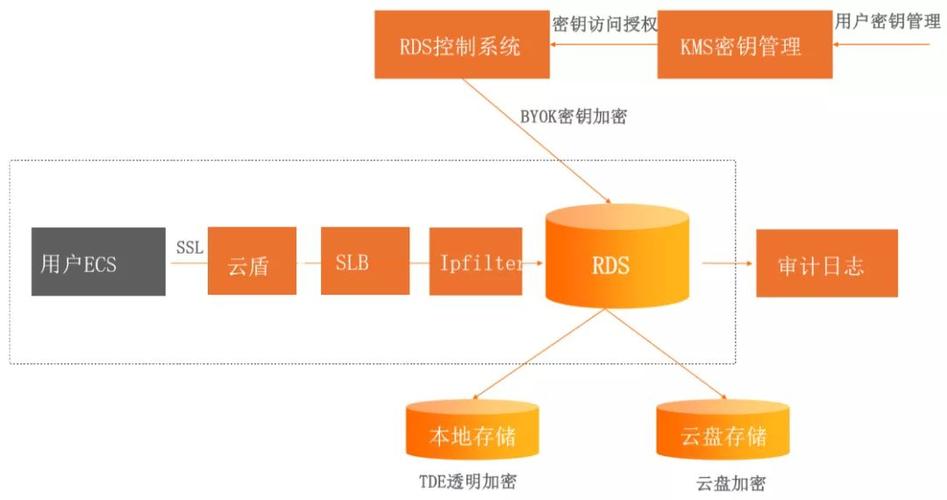
关系型数据库:通常作为独立的服务运行,对外提供统一的访问接口,易于管理和维护。
分布式数据库:每个节点可以独立运作,但在整体上需要有效的协调和管理机制来保持数据的一致性和系统的稳定性。
针对上述分析,可以考虑以下几点建议:
对于需要快速响应和高并发处理的互联网服务,分布式数据库可能是更合适的选择。
当业务逻辑复杂,数据安全性和一致性至关重要时,关系型数据库将是更优的选择。
对于初创企业或者预算有限的项目,关系型数据库可能因成本效益比较高而更受青睐。
关系型数据库和分布式数据库虽然都能提供数据存储和管理的解决方案,但它们的设计初衷和擅长的领域不同,关系型数据库更适合那些需要强大事务管理和严格数据一致性的业务,而分布式数据库则更适合处理大规模数据和高并发请求的场景,在实际应用中,应根据项目的具体需求和预期目标来选择合适的数据库类型,随着技术的发展,两种数据库之间也在逐渐出现融合的趋势,如分布式关系型数据库的出现,这为未来的数据库选择提供了更多的可能性和灵活性。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复