
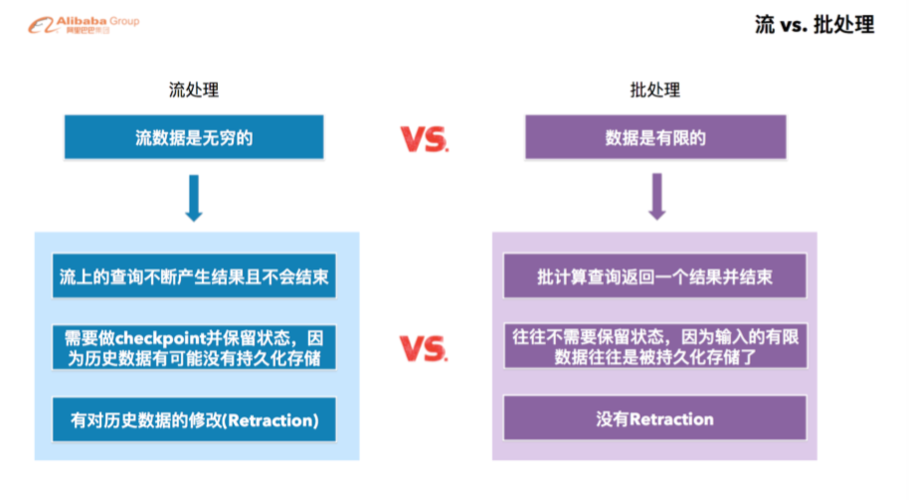
大数据的批处理和流处理是两种不同的数据处理范型,在创建批处理作业时需要细致规划和执行,以确保数据的批量导入、导出和业务逻辑计算可以高效、可靠地完成,下面将详细解析如何创建高效的批处理作业:

(图片来源网络,侵删)
1、选择合适的框架与工具
兼容性与可移植性:选择能与多种数据处理引擎兼容的框架,如Apache Beam,它能提高应用程序的可移植性,并且易于在不同的处理引擎之间无缝切换。
健壮性与可靠性:考虑框架的健壮性和可靠性,确保批处理作业不会因为无效或错误数据导致程序崩溃,通过跟踪、监控和日志以及相关处理策略实现批作业的可靠执行。
2、理解批处理框架的特点
Spring Batch的优势:如果使用Java开发,可以考虑使用Spring Batch,这是一个优秀的批处理框架,提供了丰富的可扩展组件,支持处理大量数据,同时保持了业务逻辑与处理步骤的清晰分离。
Flink的流批一体特性:对于需要低延迟的流式数据处理和高吞吐的批处理,可以考虑使用Apache Flink,它能够将批处理任务作为流处理的子集加以处理。
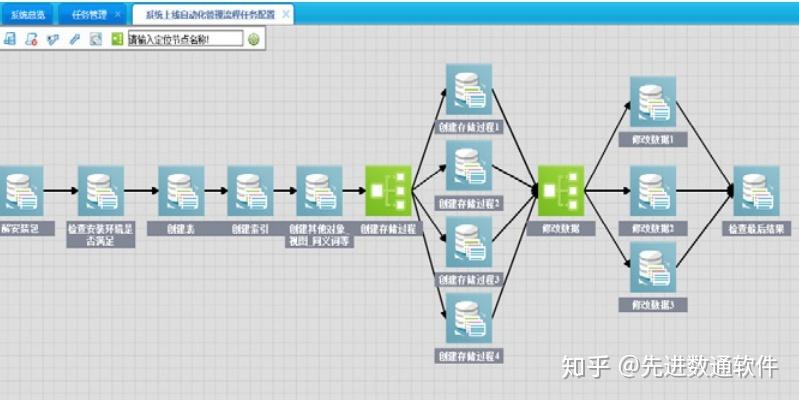
3、设计批处理作业流程
作业分解:明确把批处理作业分解为读取、处理和写入三个阶段,分别对应数据的输入、业务逻辑的处理和数据的输出。
(图片来源网络,侵删)
容错机制:设计可靠的异常处理和数据恢复机制,包括重试、跳过和重启等策略,保证作业的稳定运行。
创建一个高效、可靠的批处理作业不仅需要考虑数据处理的技术层面,还要关注整体的系统设计、性能优化和故障处理,随着技术的发展,批处理框架和工具也在不断进步,为大数据集的处理提供了强大的支持。
(图片来源网络,侵删)
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复