
Spark是一款快速的通用集群计算系统,配置于大量数据处理和分析的场景中,特别适用于大数据工作,下面将详细解析在Linux环境下搭建Spark的流程:

1、环境准备
软件准备:确保系统中已安装Java(推荐使用Java 8),因为Spark框架是用Scala语言编写的,运行在JVM上,接下来需要安装Hadoop系统,因为Spark可以运行在Hadoop之上,利用其分布式存储和计算能力。
Hadoop集群搭建:如果需要运行在Hadoop集群之上,需要预先配置好Hadoop环境,包括HDFS和YARN的设置,这样Spark才能通过YARN来调度任务。
2、下载与安装
下载Spark:访问Spark官网下载最新版本的Spark,选择对应的Hadoop版本和Linux系统版本进行下载。
创建目录并解压:在适当的位置(如/export/servers)创建Spark安装目录,并将下载的Spark压缩包解压到该目录中。
3、配置Spark
配置文件的设置:进入Spark的conf目录,根据实际需求编辑sparkdefaults.conf文件,在这个文件中可以设置各种运行参数,如内存大小、核心数等。
环境变量的配置:为了方便启动Spark和执行Spark命令,建议将Spark的bin目录添加到PATH环境变量中。
4、启动Spark
独立模式启动:可以在单机上以独立模式启动Spark,通过执行sparkshell或sparksubmit启动Spark并运行程序。
集群模式启动:如果需要在集群上运行Spark,可以通过startall.sh脚本启动集群中的所有Spark服务,包括Master和Workers。
5、测试与验证
运行示例程序:启动Spark后,可以运行内建的示例程序,如Pi示例或Word Count程序,来验证Spark是否正确安装和配置。
6、集成开发环境(IDE)配置
IDE插件安装:如果使用IDE进行Spark应用开发,如IntelliJ或Eclipse,可以安装相应的Spark插件,方便代码编写和调试。
7、深入理解Spark
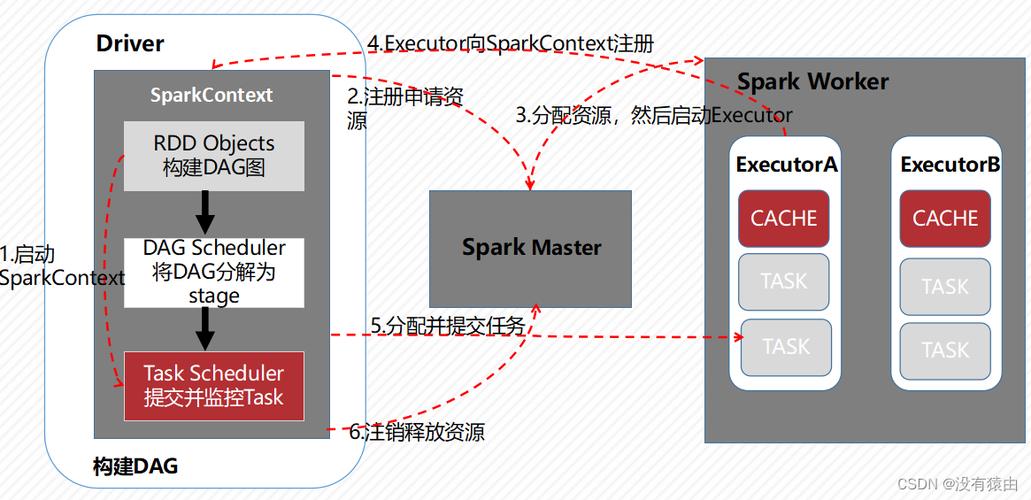
学习Spark架构:为了更好地使用Spark,了解其整体架构和基本术语是必要的,熟悉Spark的运行架构和RDD(弹性分布式数据集)的原理可以帮助更有效地编程和调优。
在完成上述步骤后,基本上已经完成了Spark的搭建,为确保正确无误,在此过程中还应注意以下几点:
确认所有节点间网络互通,并且防火墙设置不会阻止Spark组件间的通信。
确保Hadoop的配置文件(如coresite.xml和hdfssite.xml)与Spark配置文件相兼容。
监控Spark运行状态,可通过Spark提供的Web UI查看各个作业的运行状况。
搭建Spark涉及准备工作、软件安装、配置调整、服务启动和测试验证等步骤,每一个步骤都需细致执行,以确保Spark能够在后续的大数据处理任务中稳定高效运行。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复