
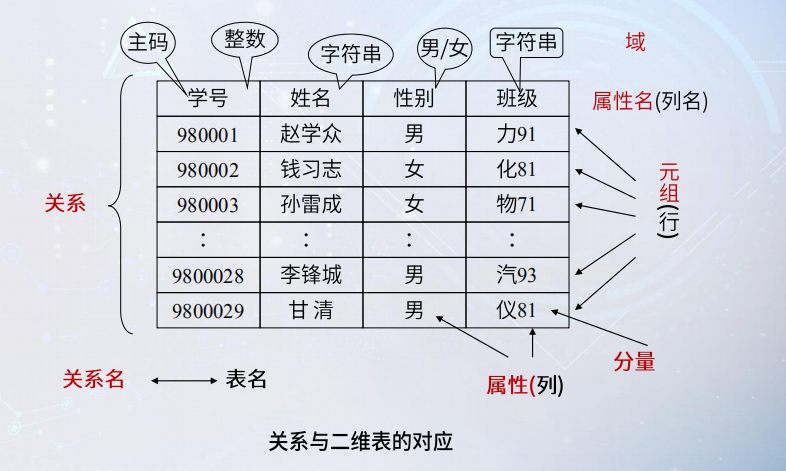
关系数据库表结构设计

规范化设计
关系型数据库表结构设计中,规范化(Normalization)是一个至关重要的步骤,其主要目的是减少数据冗余、提高数据一致性和完整性,同时优化数据库的性能,规范化通常通过一系列范式来实施:
1、第一范式(1NF):要求每一列都是不可分割的原子项,并且确保每个字段都是原子的,即不能再进一步分解,这可以有效避免数据冗余并提升查询性能。
2、第二范式(2NF):在满足第一范式的基础上,要求非主键列必须完全依赖于整个主键,而不是主键的一部分,这样可以保证数据一致性并减少数据冗余。
3、第三范式(3NF):满足第二范式的前提下,要求非主键列之间不存在传递依赖关系,即每个非主键字段应只与主键有直接关联,而不应与其他非主键字段产生关联,这有助于确保数据的完整性,减少数据间的不必要联系。
反范式化设计
虽然规范化设计能带来数据一致性和完整性,但在某些情况下,为了提高查询效率和性能,需要采用反范式化设计:
1、适度冗余:在概念数据模型设计时遵循规范化,而在物理数据模型设计时,可以适当降低范式标准,增加字段,允许部分冗余,达到以空间换时间的目的。
2、索引优化:通过冗余一些常用查询字段,减少表的关联操作,提高索引优化的效果。
最佳实践
1、合理的字段类型选择:根据数据的实际特点选择合适的字段类型,如整型、浮点型、字符型或文本型,有助于节省存储空间并提高查询效率。
2、设置主键和外键:为每个表设置主键以确保数据的唯一性,同时根据业务逻辑设置外键约束,保证表之间的关联性和数据一致性。
3、合理使用索引:索引是提高查询效率的重要手段,但过多索引会增加数据库的存储空间和写入开销,需要根据实际情况合理创建索引。
4、考虑扩展性和可维护性:设计时应考虑未来的业务发展和数据增长,预留扩展字段和冗余字段,保持表结构的清晰和简洁,方便未来的维护和优化。
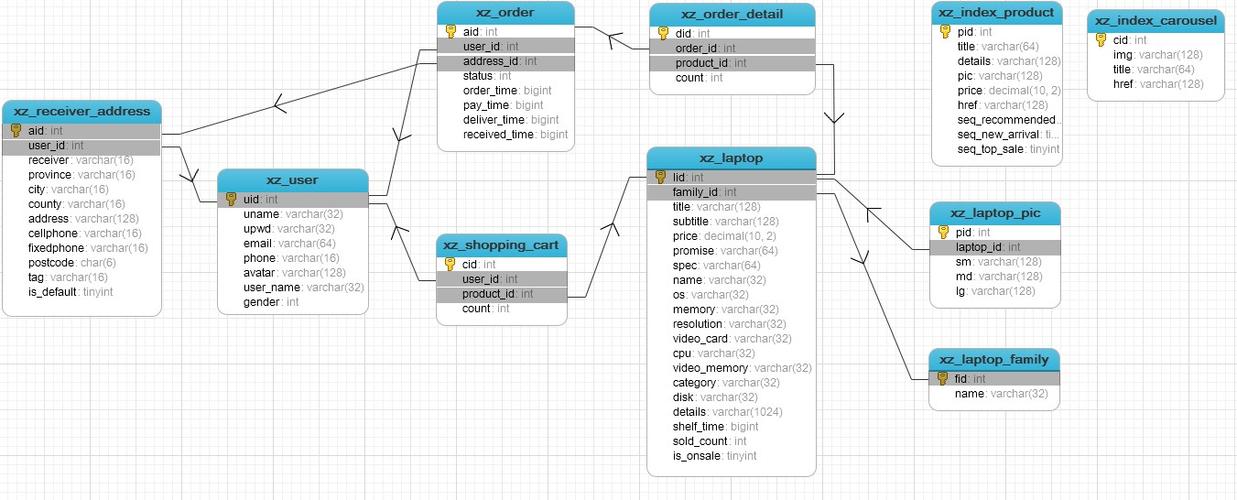
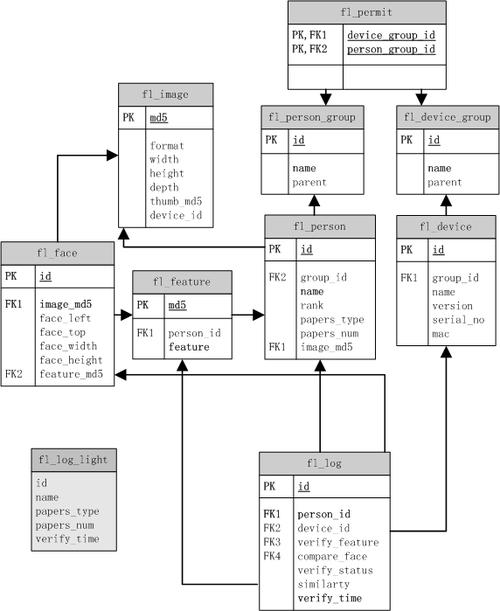
HUDI表结构设计
Hudi (Hadoop Upserts Deletes and Incrementals) 是一个基于Apache Hadoop的数据管理框架,支持对大规模数据进行高效的插入、更新和删除操作,Hudi的设计哲学和实现方式对于理解现代数据湖架构及其优势具有重要意义:
1、动态Schema和表结构变更:Hudi采用读时模式(Schema on Read)设计,允许动态Schema和表结构的变更,相比写时模式(Schema on Write)提供了更大的灵活性和可扩展性。
2、高效的任务调度和管理:通过高容错的任务调度管理策略,保证作业即使失败重跑也不会影响效率,解决了传统数据处理中的任务失败问题。
3、数据湖架构:Hudi提供标准化的统一解决方案,解决了大规模数据存储问题,同时支持数据的快速存储和快照,以及数据回溯和恢复功能,极大增强了数据管理的可靠性和效率。
无论是传统的关系型数据库还是现代的数据湖架构,表结构设计都是数据管理不可或缺的一环,良好的设计不仅能够提高数据的准确性和查询效率,还能为未来的业务发展和数据增长提供坚实的基础,在实际操作中,应结合规范化和反范式化设计的优点,遵循最佳实践原则,同时也要灵活应用新技术和策略,以适应不断变化的业务需求和技术环境。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复