
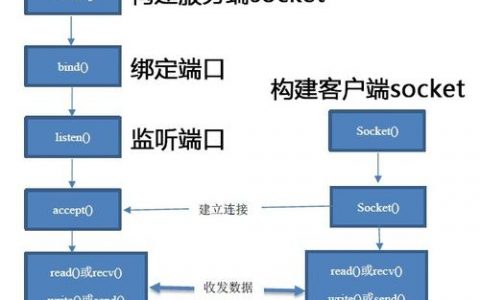
在数据库管理中,经常会遇到原数据被合并存储,但实际业务需求需要拆分查询的情况,原本将多个表的数据合并到一个表中,或通过JSON、XML等格式将多个字段合并存储,此时若需按拆分后的条件进行查询,就需要采用特定的技术手段,本文将系统介绍从合并数据中查找拆分数据库的方法,涵盖场景分析、技术工具、操作步骤及注意事项。

合并数据的常见形式与拆分需求
合并数据的存储形式多样,常见的包括:单表多字段合并(如将姓名、电话、地址合并为一个字符串字段)、多表关联后合并(如通过LEFT JOIN将订单表与用户表合并为一个大表)、JSON/XML格式嵌套存储(如将用户的多条订单信息以JSON数组形式存入用户表的某个字段),拆分需求则因业务场景而异,需按合并前的独立字段筛选数据、需统计合并前各子集的数据量、需将合并数据还原为原始多表结构等,明确合并形式与拆分需求是选择解决方案的前提。
基于字符串处理的拆分方法
若合并数据是通过特定分隔符将多个字段或值拼接而成(如用逗号分隔的ID列表、用竖线分隔的属性字符串),可通过字符串函数拆分,以MySQL为例,可使用SUBSTRING_INDEX函数按分隔符截取子串,再结合UNION ALL将拆分结果转为多行数据,某表user_tags存储用户的多个标签,格式为"1,3,5",需查询包含标签”3″的用户,可通过以下方式实现:
SELECT user_id FROM user_tags WHERE ',' + tags + ',' LIKE '%,3,%';
若需将合并标签拆分为多行记录,可使用辅助表或JSON_TABLE(MySQL 8.0+):
SELECT user_id, tag_value
FROM user_tags
CROSS JOIN JSON_TABLE(
CONCAT('["', REPLACE(tags, ',', '","'), '"]'),
'$[*]' COLUMNS(tag_value INT PATH '$')
) AS tags; 优点:无需修改表结构,适用于简单分隔符场景;缺点:分隔符冲突时易出错,复杂嵌套结构难以处理。
基于JSON/XML的解析方法
对于JSON/XML格式合并的数据,现代数据库普遍提供原生解析函数,以JSON为例,MySQL的JSON_EXTRACT、PostgreSQL的->>、SQL Server的JSON_VALUE可直接提取字段值,某表user_orders存储用户的订单JSON数据:

{"orders": [{"order_id": 1001, "amount": 200}, {"order_id": 1002, "amount": 150}]} 需查询订单金额大于100的用户,可使用:
SELECT user_id FROM user_orders WHERE JSON_EXTRACT(orders, '$.orders[*].amount') > 100;
若需将JSON数组拆分为多行,MySQL的JSON_TABLE、PostgreSQL的jsonb_array_elements可高效实现:
SELECT user_id, order_id, amount
FROM user_orders
CROSS JOIN JSON_TABLE(
orders,
'$.orders[*]' COLUMNS(
order_id INT PATH '$.order_id',
amount DECIMAL PATH '$.amount'
)
) AS orders; 优点:支持复杂嵌套结构,查询效率高;缺点:要求数据库版本支持JSON函数,且JSON格式需规范。
基于关联表的逆向拆分方法
若合并数据是多个表通过UNION ALL或JOIN生成,可通过分析原表结构逆向拆分,原数据可能是users表与orders表通过LEFT JOIN合并,此时可通过以下步骤拆分:
- 识别关联字段:确定合并时用于关联的字段(如
user_id); - 重建关联查询:按原业务逻辑重新关联表,
SELECT u.user_id, u.name, o.order_id, o.amount FROM users u LEFT JOIN orders o ON u.user_id = o.user_id;
- 使用临时表或视图:若需频繁查询,可创建视图存储拆分后的结果:
CREATE VIEW user_orders_split AS SELECT u.user_id, u.name, o.order_id, o.amount FROM users u LEFT JOIN orders o ON u.user_id = o.user_id;
优点:还原数据原始关系,支持复杂业务逻辑;缺点:需明确原表结构,关联查询可能影响性能。

使用ETL工具进行数据拆分
对于大规模或复杂的合并数据,可通过ETL(Extract-Transform-Load)工具处理。
- Extract:从合并表中提取数据;
- Transform:使用工具内置函数(如Kettle的
Split Fields、Python的pandas.json_normalize)拆分数据; - Load:将拆分后的数据写入新表或临时表。
以Python为例:import pandas as pd df = pd.read_sql("SELECT user_id, orders FROM user_orders", conn) df_orders = pd.json_normalize(df['orders'], 'orders', ['user_id']) df_orders.to_sql('orders_split', conn, if_exists='replace', index=False)优点:支持批量处理,可自定义拆分逻辑;缺点:需额外工具配置,存在数据同步延迟。
注意事项与优化建议
- 性能优化:拆分查询时,确保合并字段有索引,避免全表扫描;对JSON拆分,可考虑生成列(Generated Column)预提取字段;
- 数据一致性:拆分后需验证数据完整性,避免因合并数据格式错误导致拆分异常;
- 版本兼容性:部分数据库函数(如
JSON_TABLE)版本要求较高,需确认环境支持; - 业务影响:频繁拆分可能影响查询性能,可权衡是否通过冗余存储或物化视图优化。
相关问答FAQs
Q1: 合并数据中包含分隔符冲突(如字段值本身包含逗号),如何安全拆分?
A: 可采用多字符分隔符(如)或转义符处理,或直接使用JSON/XML格式存储,若已用逗号分隔,可通过REPLACE函数替换字段中的逗号(如将"a,b"替换为"a##b"),再按拆分,最后还原原始逗号,例如MySQL中:
SELECT user_id, SUBSTRING_INDEX(SUBSTRING_INDEX(tags, ',', n), ',', -1) AS tag
FROM user_tags
JOIN (
SELECT 1 AS n UNION SELECT 2 UNION SELECT 3
) AS numbers
WHERE CHAR_LENGTH(tags) - CHAR_LENGTH(REPLACE(tags, ',', '')) >= n - 1; Q2: 如何判断合并数据是否适合通过ETL工具拆分,而非SQL函数处理?
A: 当满足以下条件时,建议优先选择ETL工具:① 数据量超过百万级,SQL拆分查询效率低;② 拆分逻辑复杂(如需正则匹配、多级嵌套处理);③ 需跨系统同步拆分结果(如从MySQL导出到Elasticsearch),若数据量小且拆分规则简单(如固定分隔符),SQL函数更高效;反之,ETL工具的灵活性和批处理能力更具优势。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!



发表回复