
GPU云运算服务器系统_GPU调度


GPU云运算服务器系统是一个集成了高性能图形处理单元(GPU)的计算服务,主要用于提供强大的并行处理能力和高速度的浮点运算能力,它广泛应用于深度学习、科学计算、图形渲染等场景中,对处理大量数据和复杂计算需求尤为有效。
GPU调度即指在GPU云运算服务器系统中,根据任务需求,合理分配和管理GPU资源的过程,有效的GPU调度能显著提高资源的利用率和处理速度,对于提升整个系统的性能和效率至关重要。
GPU云运算服务器系统中的GPU调度主要涉及以下几个方面:
1、资源分配:根据不同用户和任务的需求,动态分配合适的GPU资源,有些任务可能更侧重于计算密集型操作,而另一些则可能需要更多的显存容量。
2、任务队列管理:实现任务的有序执行,鉴于多个任务可能会竞争同一GPU资源,合理的任务队列管理能够确保所有任务高效、公平地获取资源。
3、负载均衡:通过监控每个GPU的负载情况,动态调整任务分布,避免某些GPU过载而其他GPU空闲的情况发生。
4、故障容忍和恢复:在GPU或相关服务出现故障时,能够迅速进行故障切换和任务恢复,减少服务中断时间。
5、性能监控与优化:实时监控GPU使用情况和任务运行状态,根据监控数据优化调度策略,改善系统整体性能。
6、安全隔离:尤其是在多租户共享GPU资源的场景中,保证不同用户的任务在资源使用上的隔离,避免数据泄露和相互干扰。
7、资源超卖管理:针对虚拟化的GPU资源,进行超卖管理,即在保证性能的前提下,适度超出物理资源的实际数量进行资源分配,以提升资源利用率。
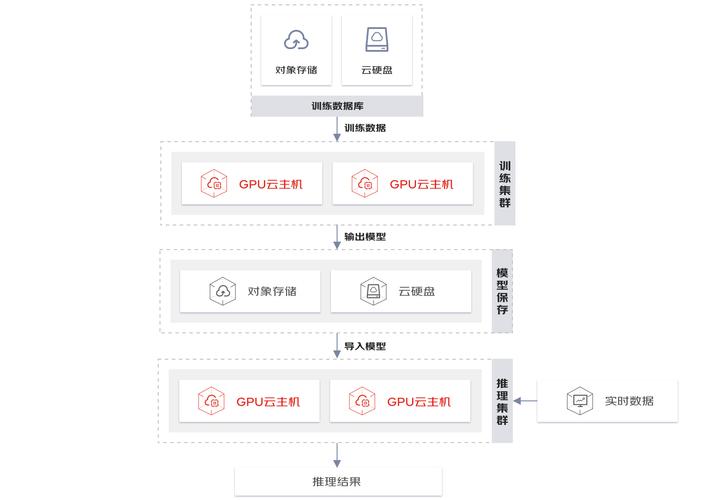
针对GPU调度的实施,当前主流的技术包括使用容器编排工具如Kubernetes进行资源管理,以及利用专门的GPU虚拟化技术,如NVIDIA提供的GPU虚拟化解决方案,包括vGPU等技术来实现资源的切分和共享,各种框架如Tensorflow、Pytorch等深度学习框架的分布式训练功能也在一定程度上依赖于有效的GPU调度策略来提升计算效率。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复