
Elastic MapReduce (EMR) 是亚马逊网络服务(AWS)提供的一项服务,它允许用户在Amazon Web Services云平台上运行Hadoop和Spark等大数据框架,EMR提供了一种简单、快速且成本效益高的方法来处理大量数据。
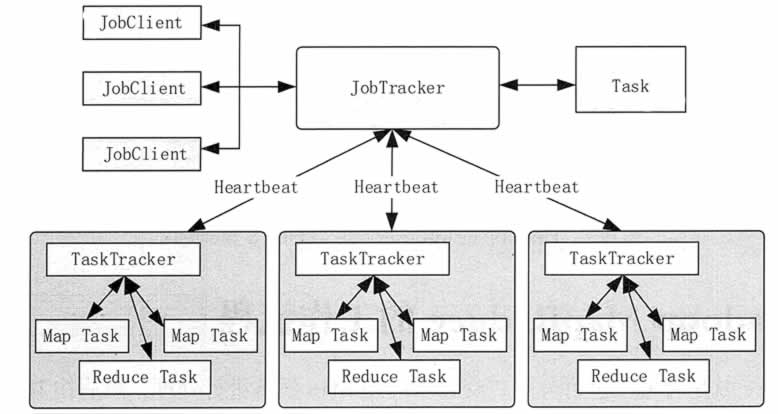

Elastic MapReduce的工作原理
EMR基于MapReduce编程模型,这是一种用于处理大数据集的计算模型,MapReduce作业通常分为两个阶段:Map阶段和Reduce阶段,在Map阶段,输入数据被分割成多个小数据块,每个数据块由一个Map任务处理,Map任务将输入数据转换为一组键值对,这些键值对根据键进行排序和分组,以便同一键的所有值都发送到同一个Reduce任务,在Reduce阶段,每个Reduce任务处理一组键值对,并生成输出结果。
EMR的主要特点
易于使用:EMR提供了一个管理控制台,用户可以通过这个控制台创建、配置和管理集群。
灵活性:用户可以自由选择各种开源应用程序,如Hadoop、Presto、Spark、Hive等。
可伸缩性:EMR可以根据需要自动扩展或缩小集群的大小。
成本效益:EMR按实际使用时间收费,没有前期费用或终止费用。
使用EMR的步骤
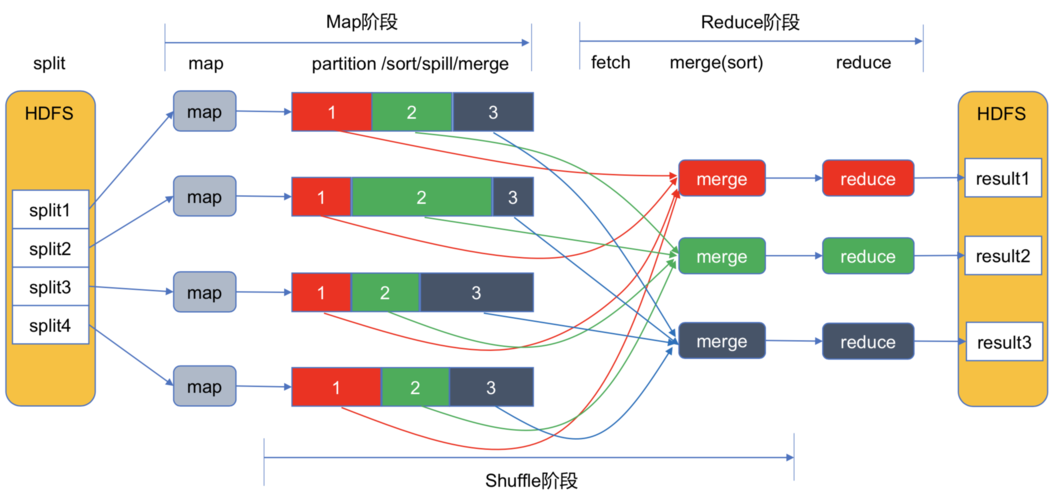
1、创建集群:在AWS管理控制台中,选择"Create cluster",然后选择所需的实例类型、数量和配置。
2、配置集群:可以配置Hadoop、Spark、Hive等应用程序的配置参数。
3、上传数据:可以使用Amazon S3作为数据存储,将数据上传到S3中。
4、运行作业:通过EMR管理控制台提交MapReduce作业。
5、监控作业:可以在EMR管理控制台中查看作业的状态和性能指标。
6、获取结果:作业完成后,可以将结果保存到S3中,或下载到本地机器上。
EMR的优势
无需维护硬件:EMR运行在AWS的基础设施上,无需购买和维护硬件。

自动故障恢复:如果某个节点失败,EMR会自动启动新的节点替换失败的节点。
集成其他AWS服务:EMR可以与Amazon S3、Amazon DynamoDB等AWS服务无缝集成。
EMR的限制
成本:虽然EMR按实际使用时间收费,但大规模数据处理的成本可能会很高。
学习曲线:对于不熟悉大数据处理的用户,可能需要一些时间来学习和理解EMR的使用。
相关的问题和解答
1、问题:EMR支持哪些大数据框架?
解答:EMR支持多种大数据框架,包括Hadoop、Spark、Hive、Pig、Presto等。
2、问题:如何优化EMR的性能?
解答:优化EMR的性能的方法有很多,包括但不限于:选择合适的实例类型和数量,合理配置应用程序的参数,使用Amazon S3进行数据存储和传输,以及合理设计MapReduce作业以减少数据传输和计算的复杂性。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复