
FPTree(Frequent Pattern Tree)是一种用于挖掘频繁项集的有效数据结构,在机器学习中,FPTree常用于关联规则学习、频繁模式挖掘等任务,下面将详细介绍FPTree的构建过程以及其在机器学习端到端场景中的应用。
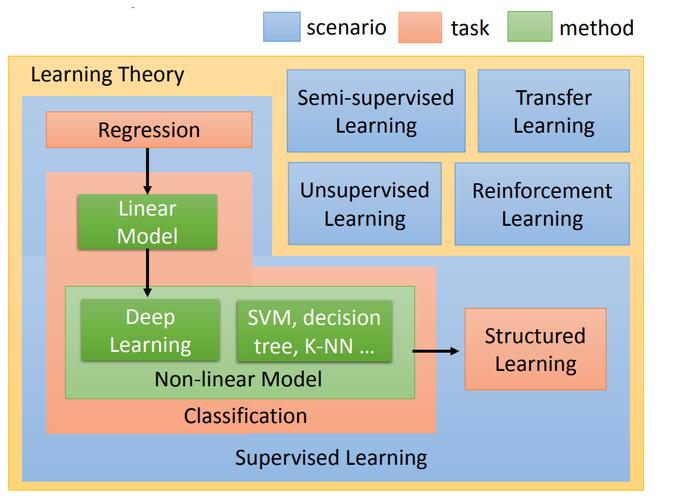

1、FPTree的构建过程
FPTree的构建过程主要包括两个步骤:扫描数据集和构建FPTree。
1.1 扫描数据集
对数据集进行一次扫描,计算每个项的频率,按照项的频率从高到低排序,并记录下每个项的支持度,支持度是指一个项在所有事务中出现的次数与总事务数之比。
1.2 构建FPTree
根据排序后的支持度信息,逐个将项插入到FPTree中,具体步骤如下:
如果FPTree为空,则将当前项作为根节点插入;
如果当前项已经在FPTree中存在,则将其频率加一;
如果当前项不在FPTree中存在,则创建一个新的节点,并将当前项作为该节点的标签,将该节点插入到FPTree中。
2、FPTree在机器学习端到端场景中的应用
FPTree在机器学习中主要用于关联规则学习和频繁模式挖掘任务,下面以关联规则学习为例介绍其应用过程。
2.1 关联规则学习
关联规则学习的目标是发现数据集中项之间的关联关系,通过使用FPTree,可以高效地挖掘频繁项集和关联规则,具体步骤如下:
构建FPTree:使用上述的构建过程构建FPTree;
挖掘频繁项集:从FPTree中挖掘出满足最小支持度的频繁项集;
生成关联规则:根据频繁项集生成满足最小置信度的关联规则。
3、相关问题与解答
问题1:为什么使用FPTree可以提高关联规则学习的效率?
答:使用FPTree可以提高关联规则学习的效率主要有以下几个原因:
压缩存储:FPTree通过压缩存储的方式减少了数据的存储空间,使得算法能够处理大规模数据集;
减少扫描次数:相比于传统的Apriori算法需要多次扫描数据集,FPTree只需要一次扫描即可完成频繁项集的挖掘;
剪枝策略:FPTree采用了有效的剪枝策略,避免了不必要的计算和内存消耗。
问题2:除了关联规则学习,FPTree还可以应用于哪些机器学习任务?
答:除了关联规则学习,FPTree还可以应用于以下机器学习任务:
频繁模式挖掘:除了关联规则外,FPTree还可以用于挖掘其他类型的频繁模式,如频繁子图、频繁序列等;
分类和回归任务:FPTree可以用于构建分类器和回归模型的特征向量表示,从而提高模型的性能;
聚类分析:FPTree可以用于聚类分析中的相似性度量和距离计算,帮助确定数据点之间的相似性和距离关系。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复