
端到端深度学习概述
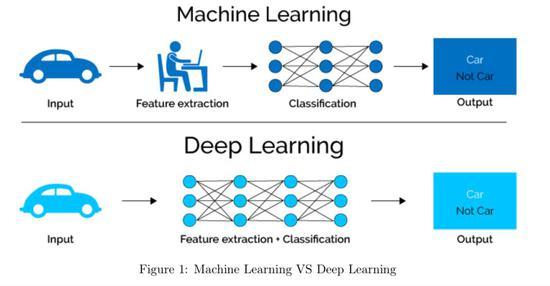

端到端深度学习是一种机器学习方法,它通过直接学习从原始输入到期望输出的映射,避免了传统机器学习中分阶段的特征提取和分类器设计,这种模型通常采用深度神经网络(如卷积神经网络cnn、循环神经网络rnn等),能够自动发现数据中的复杂模式,并用于图像识别、语音识别、自然语言处理等多种领域。
核心优势
1、简化流程:省去了繁琐的特征工程步骤,降低了建模复杂性。
2、性能提升:通过学习大量数据中的深层特征,往往能获得更好的性能。
3、自动化高:一旦训练完成,新数据的预测过程完全自动化,无需额外操作。
关键技术
数据预处理:包括数据清洗、标准化、增强等,为模型提供高质量的输入。
网络架构设计:根据问题类型选择合适的网络结构,如cnn适用于图像处理,rnn适用于序列数据处理。
损失函数选择:定义模型优化的目标,如交叉熵损失常用于分类任务。
优化算法:如sgd、adam等,用于在训练过程中更新网络权重。
正则化技术:如dropout、权重衰减等,防止过拟合。
应用案例
自动驾驶汽车:使用端到端的深度学习模型进行道路检测、障碍物识别和决策制定。
语音识别系统:将语音信号直接转换为文本,无需人工设计声音特征。
机器翻译:构建序列到序列的模型,实现不同语言间的直接翻译。
挑战与限制
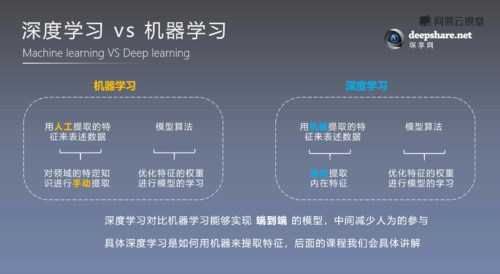
数据需求量大:端到端模型通常需要大量标注数据来避免过拟合。
计算资源密集:训练大型端到端模型需要高性能的计算资源。
可解释性差:由于模型的复杂性,其决策过程往往难以解释。
未来趋势
模型压缩与优化:为了在资源受限的设备上部署,模型压缩和加速技术将得到更多关注。
自监督学习:减少对标注数据的依赖,利用未标注数据进行预训练。
跨模态学习:整合多种类型的数据(如文本、图像、声音)进行联合学习。
相关问题与解答
q1: 端到端深度学习模型是否总是优于传统机器学习方法?
a1: 并不是,端到端深度学习模型虽然简化了流程并在许多任务上取得了卓越性能,但它们也需要大量的数据和计算资源,在某些情况下,精心设计的特征和传统机器学习模型可能更高效且易于部署和维护。
q2: 如何评估端到端深度学习模型的性能?
a2: 性能评估依赖于具体任务,对于分类任务,可以使用准确率、精确率、召回率和f1分数等指标;对于回归任务,可以使用均方误差(mse)或平均绝对误差(mae),还应考虑模型的泛化能力,通常通过在独立的测试集上评估来验证。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复