
在当今互联网时代,数据成为了重要的资源,网站通过反爬虫技术来保护自身的数据不被无授权的第三方非法获取和利用,开启网站反爬虫中的“其他爬虫”功能,虽然可以有效识别并阻止一系列自动化的爬取行为,但这一操作对网站的浏览速度的影响也成为了许多网站管理员和技术提供商关注的问题,小编将探讨该功能的开启对网页浏览速度的潜在影响,并提供一些应对策略:

1、反爬虫技术的工作原理
定义及基本功能:反爬虫技术是指网站服务器通过分析访问者的请求信息来识别并限制非正常的访问请求,这包括了检测访问者的IP地址、访问频率、用户代理(UserAgent)等信息。
“其他爬虫”功能介绍:开启“其他爬虫”功能后,Web应用程序防火墙(WAF)会对各种不同用途的爬虫程序进行检测,如站点监控、访问代理、网页分析等。
2、反爬虫技术对网站浏览速度的影响
增加服务器处理负担:开启反爬虫机制意味着服务器需要对每个请求进行额外的检测和分析,这无疑增加了服务器的处理负担,可能影响到网页加载的速度。
影响用户体验:如果服务器在处理正常用户的请求时也进行同样的检测,可能会导致用户在浏览网页时感受到明显的延迟,尤其是在网络条件较差或服务器负载较高的情况下。
3、反爬虫技术的优化建议
智能识别与放行:通过智能化的识别系统,对正常用户的访问进行放行,仅对疑似爬虫行为的请求进行深度检测,从而降低对普通用户浏览体验的影响。
使用CDN加速处理分发网络(CDN)技术,减轻源服务器的负担,提高全球范围内用户的访问速度,CDN可以缓存网站的静态资源,减少服务器的运算量,间接提高处理反爬虫机制的能力。
4、爬虫技术的应对策略
修改UserAgent:爬虫开发者可以通过修改UserAgent来模拟正常浏览器的行为,减少被识别为爬虫的风险。
使用IP代理池:通过IP代理服务可以隐藏真实的IP地址,避免由于单一IP地址频繁请求而触发反爬虫机制的限制。
5、未来发展趋势
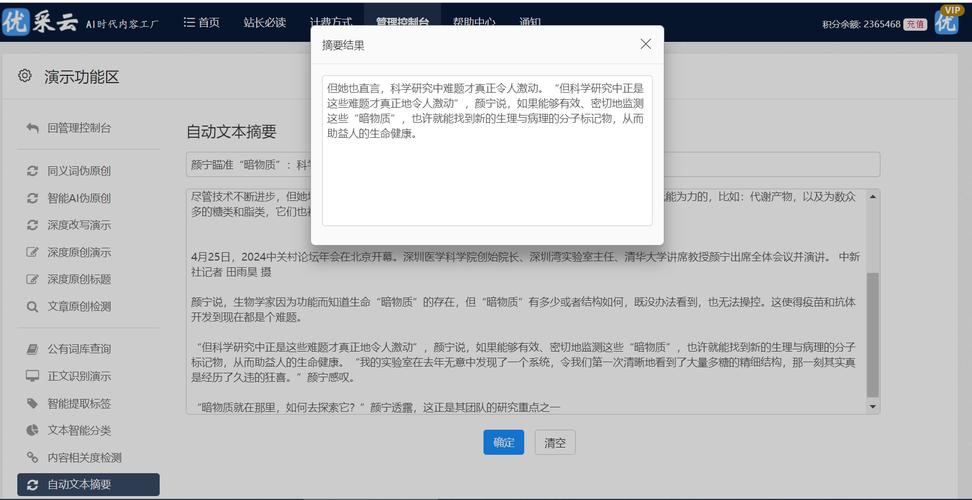
机器学习的应用:随着技术的发展,未来网站可能会采用更先进的机器学习技术来识别爬虫行为,提高识别的精准度和效率。
法律与道德规范:爬虫与反爬虫之间的博弈也将推动相关法律与道德规范的建立,促进互联网数据使用的合规性。
在理解了开启网站反爬虫中“其他爬虫”功能可能带来的影响及相应的策略之后,还可以进一步探讨一些相关的知识点和注意事项:
对于大型网站而言,如何平衡反爬虫效果和用户体验是一个值得考虑的问题,可以通过分析用户行为数据来优化反爬虫策略,仅对异常行为进行干预。
网站管理员应当定期检查和更新反爬虫策略,以应对不断进化的爬虫技术,也需要关注反爬虫机制本身是否会被滥用,造成正常用户的不便。
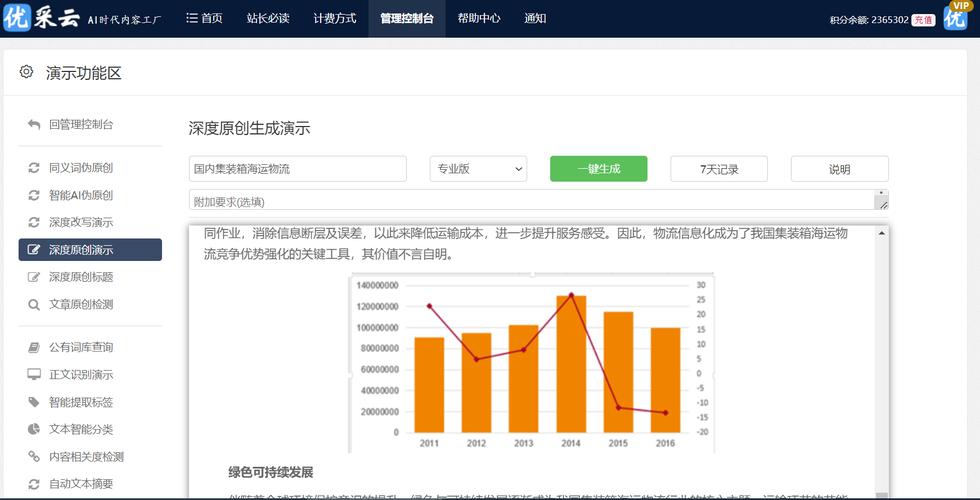
可以清晰地看到开启网站反爬虫中的“其他爬虫”功能确实存在对网页浏览速度产生影响的可能,尤其是增加服务器处理负担和影响用户体验,通过采取合理的优化措施,如智能识别系统的引入和CDN技术的使用,可以在一定程度上缓解这一问题,对于爬虫开发者来说,合理地规避反爬虫机制也是一项技术挑战,随着技术的不断进步,反爬虫技术与爬虫技术之间的较量仍将继续,但在这一过程中,重视用户体验和法律道德规范的重要性将会日益凸显。
相关问题与解答
Q1: 开启反爬虫机制是否会导致服务器成本的增加?
A1: 是的,开启反爬虫机制可能会增加服务器的运算负担,因为它需要对每个请求进行额外的分析和处理,这种增加的运算需求可能转化为更高的服务器成本,特别是当网站流量较大时。
Q2: 是否存在完全阻止所有爬虫的技术方案?
A2: 不存在能够100%阻止所有爬虫的技术方案,虽然可以通过各种技术手段大大提高爬虫的识别率和阻止率,但技术总是在不断进步的,爬虫开发者也在不断寻找新的突破方法,这是一个持续的博弈过程。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复