
table_name的表中选择不重复的column_name列值,可以使用以下查询:,,“sql,SELECT DISTINCT column_name FROM table_name;,“在mysql数据库中处理重复数据是常见的需求,特别是在数据导入、数据整合或者数据分析过程中,小编将介绍几种方法来去掉mysql数据库中的重复数据。

使用distinct 关键字
最简单的方式是在查询时使用distinct 关键字来过滤掉重复的记录,如果你有一个名为employees 的表,并且你想要获取不重复的部门列表,你可以执行以下查询:
select distinct department from employees;
这种方法不会修改原始表,它只是返回一个结果集,其中每行都是唯一的。
创建新表并插入不重复的数据
如果你想从表中永久移除重复数据,可以创建一个新表并将不重复的数据插入到新表中,以下是操作步骤:
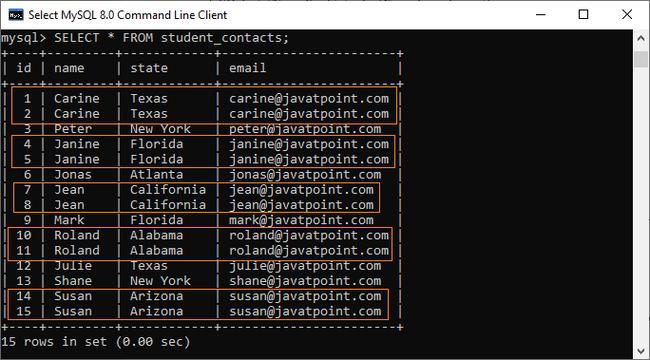
1、创建一个新的表结构与原表相同。
2、使用insert into ... select 语句结合distinct 将不重复的数据插入新表。
3、确认数据后,可以删除旧表,并将新表重命名为原表名。
示例代码如下:
create table employees_new like employees; insert into employees_new select distinct * from employees; drop table employees; rename table employees_new to employees;
使用group by 子句
如果表中有多个列,并且你想根据特定列去重,可以使用group by 子句,假设你有一个订单表,你想根据客户id去除重复的订单,可以这样写:
select * from (select * from orders order by customer_id, order_date desc) as temp group by customer_id;
这个查询首先根据customer_id 和order_date 对订单进行排序,确保每个客户的最近订单排在最前面,然后通过group by 根据customer_id 去重。
使用临时表与联结查询
在某些情况下,可能需要保留每个重复项的最新记录,这时可以先找出重复的数据,然后通过联结查询保留每个重复项的最新记录。
1、查找出所有重复的数据。
2、使用联结查询保留每个重复项的最大id或最新日期的记录。
示例代码如下:
create temporary table dup_emp as
select *
from employees
where id in (
select id from employees
group by department, name
having count(*) > 1
);
delete e from employees e
inner join dup_emp de
on e.department = de.department and e.name = de.name
where e.id < de.id;
drop temporary table if exists dup_emp; 上述代码首先创建了一个临时表dup_emp 用于存储所有重复的雇员记录,然后通过联结查询删除了每个重复组中较旧的记录。
相关问题与解答
q1: 如果表中有很多列,如何快速找出哪些列是重复的?
a1: 可以使用group by 和having 子句来检查哪些列经常一起出现,要找出经常一起重复出现的列组合,可以运行类似以下的查询:
select column1, column2, count(*) as cnt from table_name group by column1, column2 having cnt > 1;
这将列出所有column1 和column2 的组合及其出现的次数,从而帮助识别重复的列。
q2: 在删除重复数据之前,如何备份原始数据?
a2: 在操作之前备份原始数据是一个好习惯,可以使用以下语句来创建表的备份:
create table backup_table_name like table_name; insert into backup_table_name select * from table_name;
这会创建一个与原表结构相同的备份表,并将所有数据复制进去,确保在安全的地方保存备份,以便在需要时能够恢复数据。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复