
分布式数据库原理

分布式数据库是一种将数据存储和管理分布在多个计算机节点上的数据库系统,它通过将数据分散到不同的物理位置,实现了数据的高可用性、可扩展性和容错性,本文将详细介绍分布式数据库的原理和技术。
1、分布式数据库的基本原理
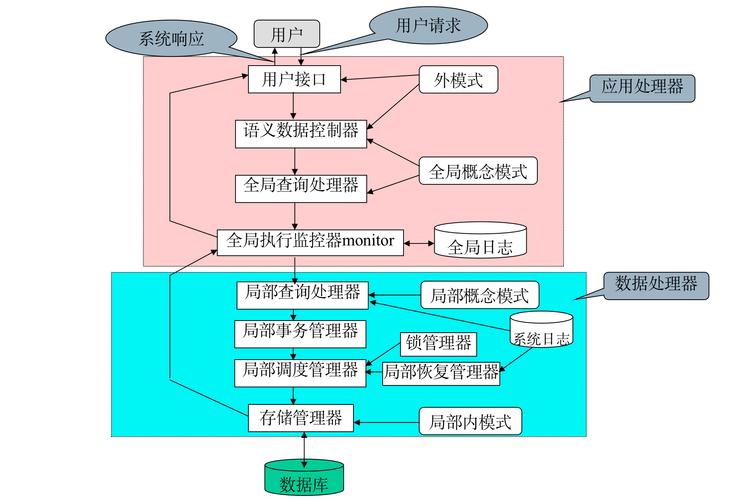
分布式数据库的基本原理是将数据和查询处理任务分散到多个节点上,每个节点负责管理一部分数据,并通过协同工作来完成全局查询处理,分布式数据库的基本原理包括以下几个方面:
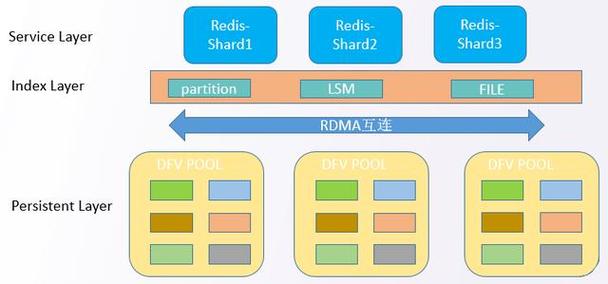
数据分片:将全局数据按照一定的规则划分为多个片段,每个片段存储在一个或多个节点上。
数据复制:为了提高数据的可用性和容错性,可以将每个数据片段复制到多个节点上。
查询处理:当用户发起查询请求时,分布式数据库系统会将查询请求分发到相关的节点上进行处理,并将结果合并返回给用户。
2、分布式数据库的关键技术
分布式数据库的关键技术主要包括数据分片、数据复制、查询处理和一致性控制等,下面分别对这些技术进行详细介绍。
2、1 数据分片
数据分片是分布式数据库中最基本的技术之一,它将全局数据按照一定的规则划分为多个片段,每个片段存储在一个或多个节点上,数据分片的主要目的是实现数据的负载均衡和并行处理。
数据分片的方法有很多,常见的有水平分片、垂直分片和混合分片等,水平分片是将全局数据按照某个属性的值进行划分,每个片段包含相同属性值的数据;垂直分片是将全局数据按照某个属性列进行划分,每个片段包含某个属性列的数据;混合分片是同时使用水平分片和垂直分片的方法。
2、2 数据复制
数据复制是分布式数据库中提高数据可用性和容错性的关键技术,它将每个数据片段复制到多个节点上,当某个节点发生故障时,可以由其他节点继续提供服务。
数据复制的方法有很多,常见的有主从复制、多主复制和链式复制等,主从复制是指一个主节点负责写入数据,多个从节点负责读取数据;多主复制是指多个主节点都可以写入数据,多个从节点都可以读取数据;链式复制是指每个节点都保存了其所有副本的指针信息,当某个节点发生故障时,可以通过指针信息找到其他副本继续提供服务。
2、3 查询处理
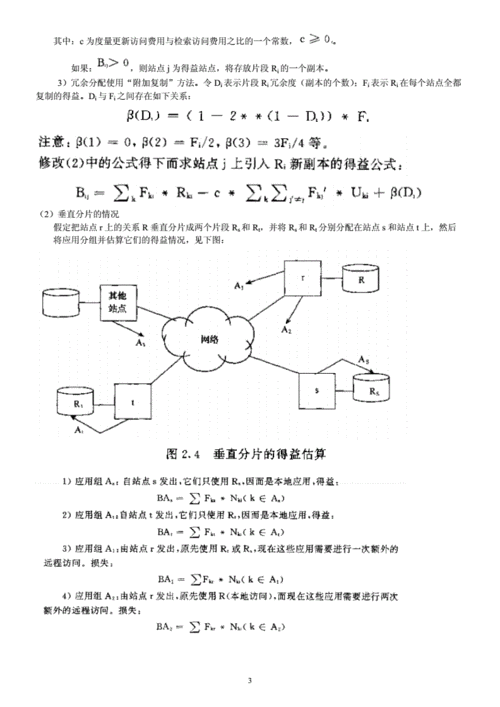
查询处理是分布式数据库中的核心功能之一,它需要将用户的查询请求分发到相关的节点上进行处理,并将结果合并返回给用户,查询处理的主要挑战是如何在保证查询性能的同时,实现数据的一致性和完整性。
查询处理的方法有很多,常见的有集中式查询处理、局部查询处理和MapReduce等,集中式查询处理是指将所有的查询请求发送到一个中心节点进行处理,然后由该节点将结果返回给用户;局部查询处理是指将查询请求发送到相关的节点上进行处理,然后将结果合并返回给用户;MapReduce是一种基于计算模型的查询处理方法,它将查询处理任务分解为一系列的Map和Reduce操作,然后在各个节点上并行执行。
2、4 一致性控制
一致性控制是分布式数据库中保证数据的一致性和完整性的关键技术,由于分布式数据库中的数据分布在多个节点上,当某个节点发生故障或网络延迟时,可能会导致数据的不一致,需要通过一致性控制技术来保证数据的一致性和完整性。
一致性控制的方法有很多,常见的有两阶段提交协议(2PC)、三阶段提交协议(3PC)和Paxos算法等,两阶段提交协议是一种常用的一致性控制方法,它通过两个阶段来保证数据的一致性和完整性;三阶段提交协议是在两阶段提交协议的基础上进行了改进,提高了系统的可用性;Paxos算法是一种基于选举的一致性控制方法,它可以在非拜占庭环境下保证数据的一致性和完整性。
3、与本文相关的问题及解答
问题1:分布式数据库中的查询处理有哪些方法?
解答:分布式数据库中的查询处理方法有很多,常见的有集中式查询处理、局部查询处理和MapReduce等,集中式查询处理是指将所有的查询请求发送到一个中心节点进行处理,然后由该节点将结果返回给用户;局部查询处理是指将查询请求发送到相关的节点上进行处理,然后将结果合并返回给用户;MapReduce是一种基于计算模型的查询处理方法,它将查询处理任务分解为一系列的Map和Reduce操作,然后在各个节点上并行执行。
问题2:分布式数据库中的一致性控制有哪些方法?
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复