
在当今互联网快速发展的背景下,传统的单体系统架构已不能满足海量用户的需求,分布式数据库的设计架构是解决大规模数据处理需求的关键方案之一,这种数据库将数据存储在不同物理位置的数据库中,从而实现数据的高效管理和访问,将详细探讨分布式数据库的架构设计,并分析其核心组成部分的功能和优化策略。
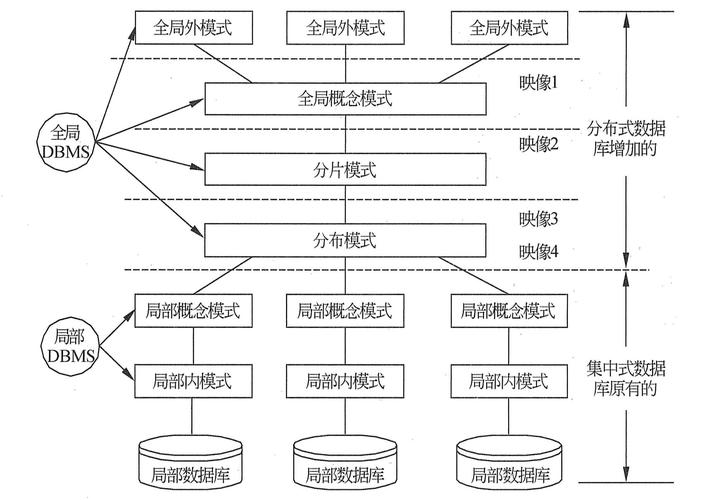

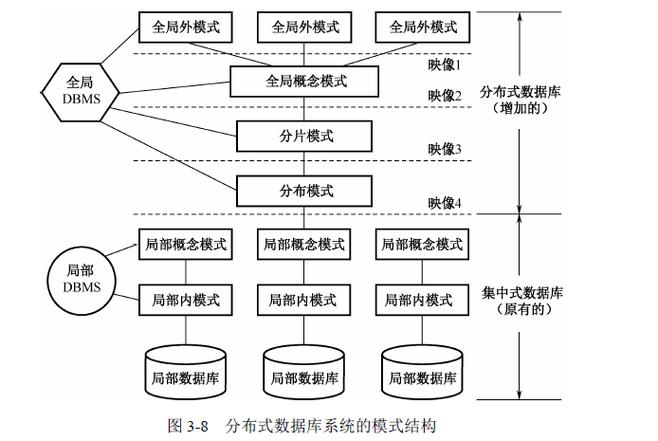
分布式数据库的基本概念与架构层次
1. 基本概念
分布式数据库是一种把数据分散存储在不同物理位置的数据库,与传统数据库将所有数据存放在一个物理存储上不同,分布式数据库通过将数据分布在多个数据库实例上,提高了数据的可访问性和容错能力。
2. 架构层次
计算层:处理数据查询和事务处理,是数据处理的核心部分,通常包括多个处理节点,每个节点负责一部分数据的处理工作。
元数据层:存储数据的结构信息和分布信息,是整个分布式数据库的管理核心,负责数据的定位和分布策略。
存储层:实际存储数据的地方,可以是一个或多个存储节点,根据数据的访问模式和容量需求动态调整。
分布式数据库的设计思路
1. 基于共享存储的架构
这种架构的特点是底层存储共用一份数据池子,上层数据库服务器层可以弹性扩展,适合作为云数据库,可以实现资源的弹性伸缩,但严格意义上这类数据库不属于分布式数据库。
2. 基于数据分片的架构
按数据的逻辑属性或键值范围进行分片,每个分片可以在不同的物理节点上独立处理,这种架构强调了分布式原理中的“无共享”架构模式,每个节点自包含,易于扩展和增强故障隔离。
分布式数据库的优化策略
1. 数据一致性保障
在设计分布式数据库时,保证跨节点数据的一致性是一大挑战,常见的策略包括使用数据复制和分区容忍的一致性协议(如Paxos或Raft)来确保数据在各个节点间的一致性。
2. 高可用性设计
通过多副本技术及故障转移机制,当某个节点失效时,系统能快速恢复,保证服务的持续性,TiDB利用多副本和Raft协议实现高可用性。
3. 性能优化
针对不同的业务访问模式,优化数据分片和负载均衡策略,如通过缓存热点数据来减少跨节点访问,或使用更高效的数据索引技术加快查询速度。
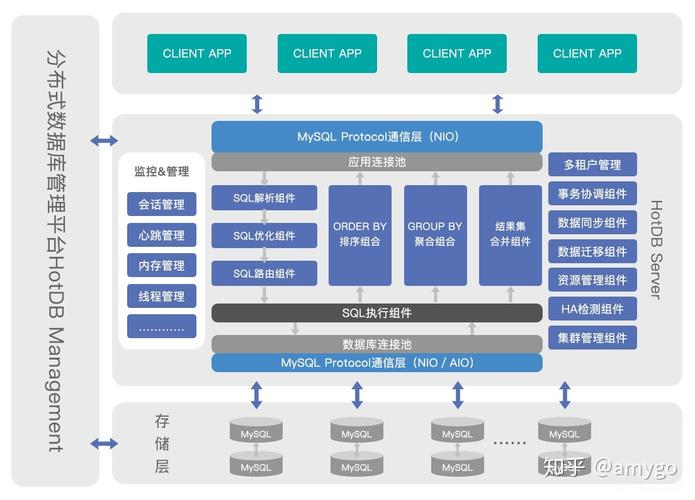
微服务架构与分布式数据库的融合
1. 微服务架构支持
微服务架构(MSA)通过划分小型、独立的服务来促进系统的灵活性和模块化,这与分布式数据库的设计理念高度契合,每个微服务可以拥有独立的数据库实例,实现服务的高内聚和低耦合。
2. 容错与扩展性
微服务架构允许系统在不影响整体的情况下对特定服务进行扩展或维护,而分布式数据库则为这些服务提供了可靠的数据支持和服务间的有效数据隔离。
分布式数据库的架构设计不仅是关于技术的选择,更多的是如何根据具体的业务需求和应用场景来进行优化和调整,从共享存储到数据分片,每种设计都有其独特的优势和应用场景,正确理解并运用这些设计原则与优化策略,能够有效提高系统的性能和可靠性,满足现代互联网时代对数据处理的高要求。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复