
MapReduce 日志介绍
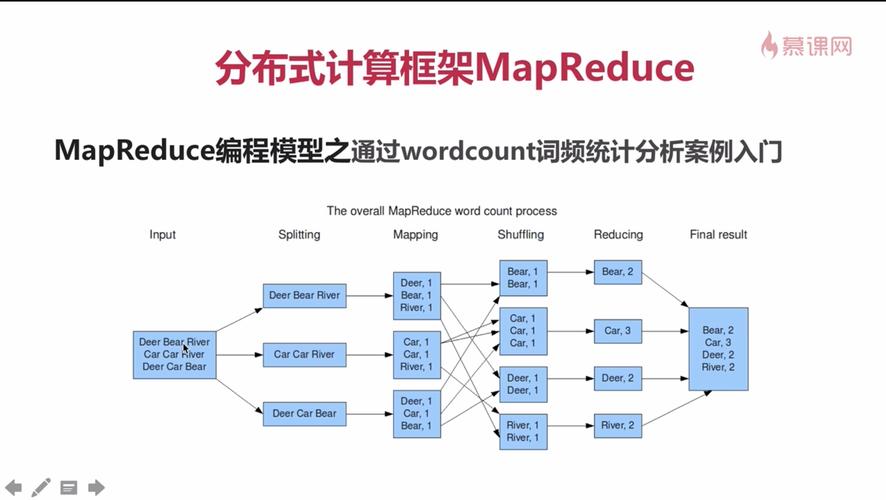

MapReduce 是 Hadoop 生态系统中的一个核心组件,用于处理大规模数据集,在运行 MapReduce 作业时,了解如何查看和解析日志对于调试和优化作业至关重要,小编将介绍如何查看 MapReduce 的日志信息。
查看 MapReduce 日志
1. 日志位置
MapReduce 作业的日志默认存储在 Hadoop 分布式文件系统(HDFS)上,通常位于/tmp/logs 或/var/log/hadoop/userlogs 目录下,具体路径可能因 Hadoop 版本和配置不同而有所差异。
2. 访问日志
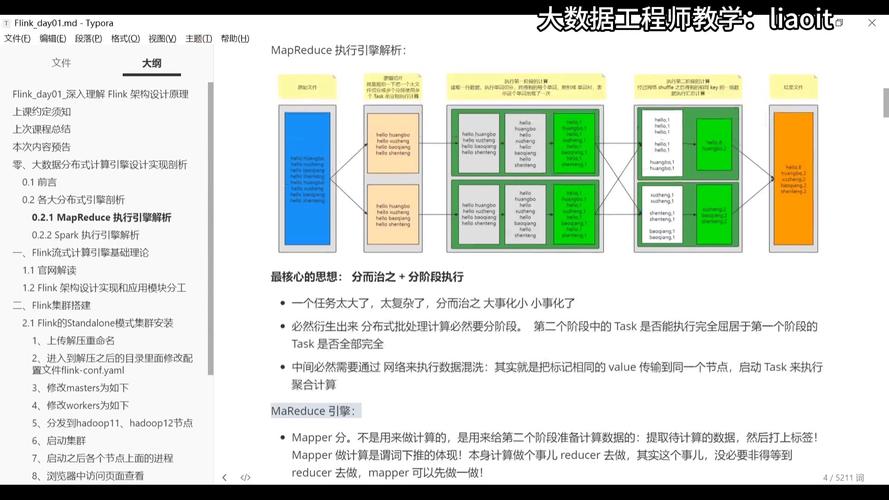
可以通过以下几种方式访问这些日志:
通过 Web 界面:Hadoop 集群配置了 Web 界面(如 Hue),可以直接通过 Web 界面查看作业日志。
使用 Hadoop 命令行工具:可以使用hadoop job logs 命令加上作业 ID 来获取日志信息。
直接访问 HDFS:可以使用hdfs dfs cat 或其他 HDFS 命令来直接查看存储在 HDFS 上的日志文件。
3. 日志内容
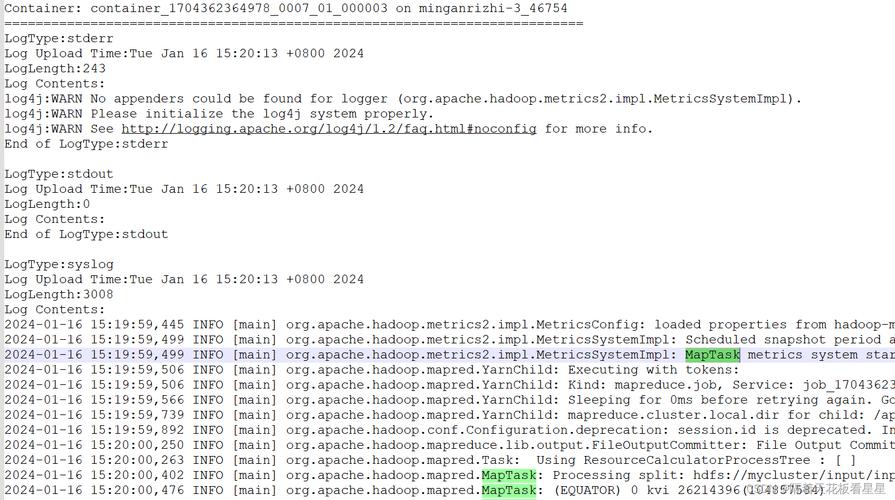
MapReduce 日志包含作业执行过程中的详细信息,
作业启动时间、完成时间和持续时间。
Map 和 Reduce 任务的数量、状态和进度。
各个任务的错误和警告信息。
Shuffle 和 Sort 过程的统计信息。
作业配置参数。
4. 日志级别
Hadoop 支持不同的日志级别,包括 ERROR、WARN、INFO、DEBUG 和 TRACE,根据需要,可以调整日志级别以控制日志信息的详细程度。
5. 日志轮转与归档
为了避免日志文件占用过多磁盘空间,Hadoop 支持日志轮转和归档,可以配置日志轮转策略,例如按时间或文件大小轮转,并设置保留的日志文件数量。
日志分析技巧
1. 关键字搜索
在日志文件中搜索特定的关键字,如 "ERROR" 或 "FAILED",可以快速定位问题所在。
2. MapReduce 计数器
利用 MapReduce 计数器可以获取作业执行过程中的各种统计信息,如已处理的输入记录数、已输出的记录数等。
3. 性能指标
关注日志中的性能指标,如 Map 和 Reduce 任务的执行时间,可以帮助识别性能瓶颈。
4. 异常堆栈跟踪
当任务失败时,异常堆栈跟踪信息对于诊断问题非常有用。
相关问题与解答
Q1: MapReduce 作业失败,我应该首先检查什么?
A1: MapReduce 作业失败,首先应该检查作业日志中的 ERROR 和 FAILED 信息,这些信息通常能指出失败的原因,检查异常堆栈跟踪以获取详细的错误上下文。
Q2: 如何配置 Hadoop 以保存更多的 MapReduce 历史日志?
A2: 可以通过修改 Hadoop 配置文件(如hadoopenv.sh 或log4j.properties)来调整日志级别和日志轮转策略,可以增加日志文件的最大保存数量,或者调整日志轮转的时间间隔,确保 HDFS 上有足够的空间来存储这些额外的日志文件。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复