
在当今数据驱动的世界中,非结构化数据的抽取成为了一个重要的研究领域,这种类型的数据包括新闻报道、文学读物等多种形式,它们不像传统的数据库信息那样以固定的格式存在,因此处理起来具有一定的挑战性,本文将对非结构化数据抽取进行详细的探讨,涵盖实体抽取、关系抽取和事件抽取三个核心方面,并辅以实用的案例分析。
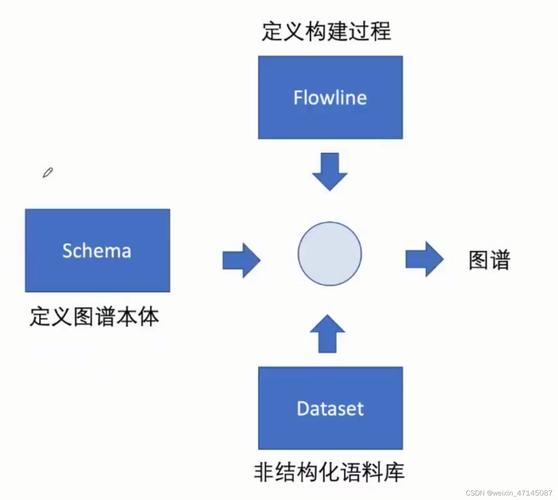

实体抽取
实体抽取是从文本中识别出具有特定意义的实体,如人名、地点、组织等,这一过程通常涉及识别名词短语,这是理解文本内容的基础,使用自然语言处理(NLP)库如NLTK可以有效地识别文本中的名词短语,进而提取相关实体。
实体抽取不仅有助于构建知识图谱,还能为更复杂的任务如关系抽取和事件抽取提供必要的输入,在新冠知识图谱的构建过程中,实体抽取帮助确定了疫情相关的地点、机构、人物等关键信息点。
关系抽取
关系抽取旨在识别并分类实体之间的关系,这包括确定两个实体之间是否存在预定义的关系类型,如“位于”、“属于”等,有效的关系抽取不仅能增强机器对文本的理解,还能促进信息的自动整合与推理。
在分析一篇关于某公司的新闻报道时,理解公司与其产品、员工以及市场行为之间的关系,对于构建该公司的知识图谱至关重要,通过关系抽取,可以系统地整理出这些信息,支持进一步的数据挖掘和知识发现。
事件抽取
事件抽取关注于从文本中识别具体的事件以及与这些事件相关的实体或论元,每个事件通常由一个动词作为触发词,围绕这个动词识别相关联的实体,形成对该事件的整体认识。
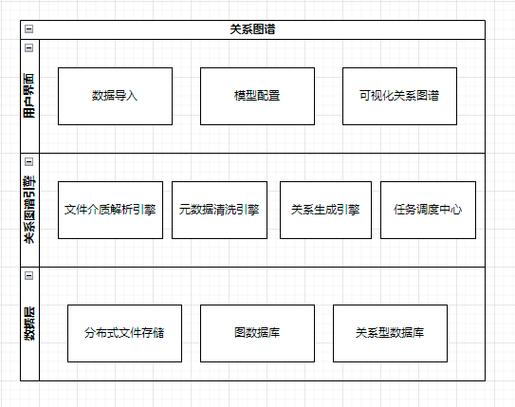
在报道一次地震的新闻文章中,事件抽取技术可以帮助识别出地震的时间、地点、受影响的区域及可能的后果等,这不仅有助于快速抽取关键信息,还可以在灾难响应和报告生成中自动化信息的处理。
案例分析
设想一个从多种新闻源自动汇总新冠疫情信息的场景,实体抽取可以从不同报道中识别出疫情相关的实体,如病毒变种、受影响的地区、治疗方法等,关系抽取能够确定这些实体之间的联系,比如某个变种首次发现的地点,事件抽取可以追踪疫情的发展,如病例数的增加、疫苗的推出等。
通过这一系列的信息处理,不仅可以实现对疫情发展态势的实时监控,还可以为政策制定者提供决策支持,为公众提供准确的信息。
非结构化数据抽取涵盖了实体抽取、关系抽取和事件抽取等多个层面,每一个环节都是理解和利用大规模文本数据不可或缺的部分,随着技术的进步,特别是在自然语言处理领域的突破,非结构化数据的抽取将变得更加高效和精准。
相关问题与解答
1、问:什么是非结构化数据抽取的主要挑战?
答:主要挑战在于文本数据的非结构化和嘈杂特性,这使得直接应用传统的数据处理方法变得困难,不同类型和来源的文本可能需要特定的处理方法,增加了处理的复杂性。
2、问:如何提高非结构化数据抽取的准确性?
答:可以通过改进自然语言处理模型、增加领域特定的预处理步骤以及采用先进的算法和工具来提高准确性,高质量的训练数据和细致的后处理也是不可或缺的。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复