
非结构化数据是指那些没有预定义数据模型、不便于直接存储在关系型数据库中的数据,它包括了各种人们创建的内容,如文本文档、电子邮件、社交媒体帖子、图像和视频等,下面将深入探讨非结构化数据的存储管理和抽取过程:
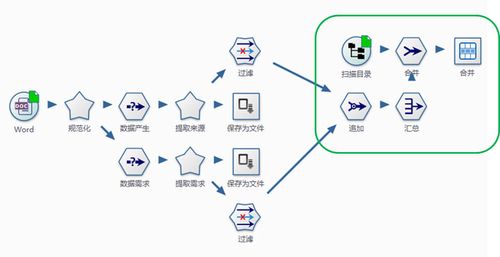

1、非结构化数据存储管理
存储形式:非结构化数据通常以文件系统、NoSQL数据库或专门的存储系统(如内容管理系统CMS)进行存储。
数据格式:非结构化数据没有固定的数据格式,这增加了处理和分析的难度。
增长速度:非结构化数据的生成速度远远超过结构化数据,这要求存储解决方案能够轻松扩展以适应数据增长。
信息含量:非结构化数据包含了大量有价值的信息,但需要通过特定的技术才能提取出来。
数据价值:非结构化数据的价值在于它们能够提供丰富的上下文信息和洞察力,但这需要有效的分析和处理手段。
2、非结构化数据抽取
前提条件:在进行非结构化数据抽取之前,需要创建相应的知识图谱并选择图谱规格,以及创建并选择本体。
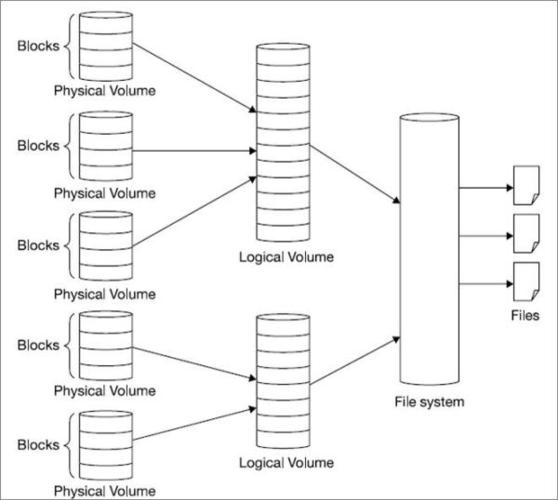
抽取过程:非结构化抽取涉及从非结构化数据中识别和提取有意义的信息,并将其转换为更易于分析和查询的格式。
技术手段:抽取技术包括自然语言处理(NLP)、文本分析、图像识别和机器学习等。
挑战:由于非结构化数据的多样性和复杂性,抽取过程中可能会遇到数据质量、数据一致性和数据集成的挑战。
应用场景:非结构化数据抽取在多个领域都有应用,如市场分析、客户洞察、风险管理和智能搜索等。
在此基础上,可以进一步探讨非结构化数据存储管理和抽取的以下策略和注意事项:
选择合适的存储解决方案,考虑到数据的类型、大小和访问频率。
确保数据的安全性和隐私保护,特别是在处理个人敏感信息时。
利用最新的技术进行数据抽取,以提高准确性和效率。
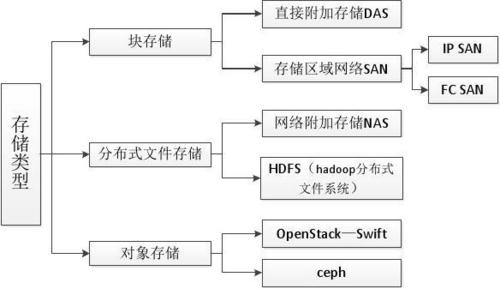
考虑使用云服务,以实现灵活的存储和计算资源管理。
定期评估存储和抽取流程,以适应不断变化的数据环境和业务需求。
非结构化数据的存储管理和抽取是一个复杂但至关重要的过程,随着技术的发展,人们有了更多的工具和方法来有效地处理这些数据,从而挖掘其潜在的巨大价值,通过合理的存储策略和高效的抽取技术,组织可以更好地利用非结构化数据,以支持决策制定和创新。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复