
在web开发中,跳转是一个常见的操作,跳转可以分为服务器跳转和客户端跳转两种,它们之间的主要区别在于控制跳转的位置不同:一个是在服务器端进行,另一个是在客户端进行。

服务器跳转
服务器跳转指的是服务器根据特定的规则或条件将请求重定向到新的URL,这通常发生在服务器接收到请求后,处理请求时发现需要将用户导向到其他资源或页面的情况,服务器跳转使用HTTP协议的响应状态码来指示客户端进行跳转,常见的跳转状态码包括:
301 Moved Permanently(永久移动)
302 Found(临时移动)
307 Temporary Redirect(临时重定向)
308 Permanent Redirect(永久重定向)
服务器跳转的一个典型例子是使用Apache或Nginx配置重定向规则,
rewrite ^(/download/.*)$ http://example.com/files$1 redirect;
这个指令将所有以/download/开头的请求重定向到http://example.com/files。
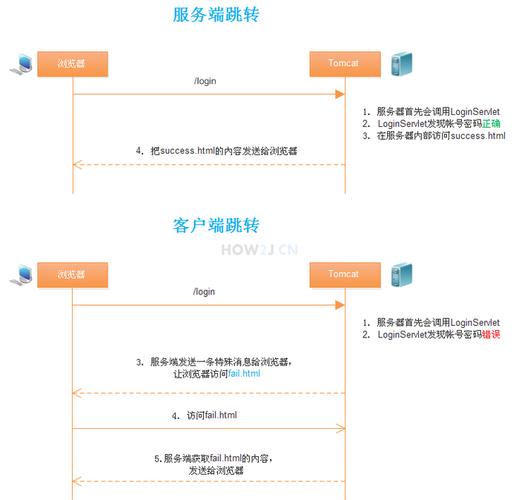
客户端跳转
客户端跳转指的是通过浏览器执行JavaScript或其他客户端脚本来实现页面的跳转,这种方式不涉及服务器端的重定向指令,而是完全由浏览器负责加载新的页面内容,常见的客户端跳转方法有:
window.location.href = "新的URL"
使用meta标签实现自动跳转,如<meta httpequiv="refresh" content="0;url=新的URL">
使用HTML的<a>标签的href属性
客户端跳转的一个例子可能是用户点击一个按钮后触发JavaScript函数,该函数改变当前页面的URL或加载新的内容。
配置权限和跳转
无论是服务器跳转还是客户端跳转,都可能涉及到权限的配置,对于服务器跳转,可以通过服务器配置文件或代码逻辑来限制特定URL的访问,确保只有具有相应权限的用户才能访问特定资源,可以配置Nginx或Apache来限制IP地址或要求HTTP认证。

对于客户端跳转,权限控制通常是通过在前端应用中实施的,前端逻辑可以根据用户的登录状态、角色或其他安全因素来决定是否允许跳转,未登录用户尝试访问需要认证的页面时可能会被重定向到登录页面。
相关的问题与解答
1、问题: 如何确保服务器跳转的安全性?
答案: 确保服务器跳转的安全性可以通过以下方式实现:
使用HTTPS加密传输来保护数据不被拦截。
检查和验证跳转的目标URL以防止开放重定向攻击。
对敏感操作实施适当的身份验证和授权机制。
定期更新和维护服务器软件以修复可能的安全漏洞。
2、问题: 客户端跳转有哪些潜在的安全风险?
答案: 客户端跳转的潜在安全风险包括:
由于跳转逻辑在客户端执行,恶意用户可能会修改客户端脚本来绕过安全限制。
如果跳转是基于用户输入的数据,则存在跨站脚本攻击(XSS)的风险。
客户端跳转可能受到中间人攻击的影响,攻击者可以篡改跳转的目标地址。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复