
服务器跳转和客户端跳转是两种不同的网页跳转方式,它们在实现机制、安全性、用户体验等方面存在显著差异,了解这些差异有助于开发者选择最合适的跳转策略,以优化网站性能和提升用户体验。
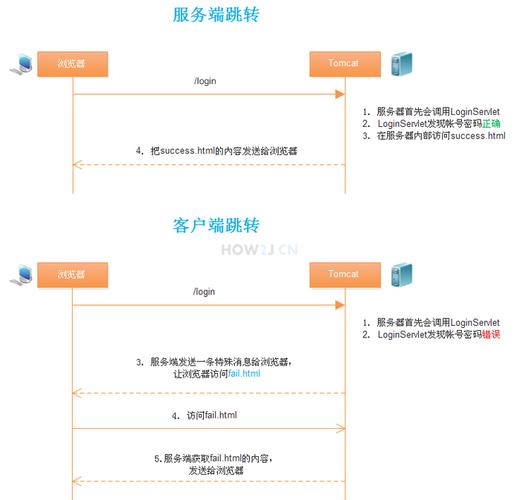

### 服务器跳转
服务器跳转指的是当用户请求一个网页时,服务器根据配置或程序逻辑决定将用户引导到另一个页面,这种跳转完全由服务器端控制,常见的实现方式有HTTP重定向(如301和302状态码)和使用服务器端脚本(如PHP, Python等)进行页面跳转。
#### 特点:
**控制权在服务器**:服务器决定跳转的目的地,不受客户端影响。
**URL变化**:跳转后,浏览器地址栏中的URL会改变,显示为最终页面的URL。
**SEO友好**:搜索引擎可以跟踪到重定向后的页面,有利于SEO。
**可传递数据**:可以通过查询字符串或服务器会话来传递数据。
**性能开销**:每次跳转都需服务器处理,增加服务器负担。

#### 配置权限和跳转示例:
假设使用Apache服务器,可通过`.htaccess`文件进行配置:
“`apache
RewriteEngine On
RewriteRule ^oldpage.html$ /newpage.html [R=301,L]
“`
这个例子中,任何对`oldpage.html`的请求都会被永久重定向(301)到`newpage.html`。
### 客户端跳转
客户端跳转是指通过在用户的浏览器上执行JavaScript或其他客户端脚本来实现页面跳转,这种方式下,跳转逻辑在客户端执行,服务器只负责提供原始页面。
#### 特点:
**控制权在客户端**:客户端代码(通常是JavaScript)决定是否以及如何跳转。
**URL可能不变**:可以使用AJAX加载新内容而不改变URL,也可以使URL变化。
**SEO不友好**:搜索引擎通常不执行或难以跟踪JavaScript跳转。
**无需服务器参与**:减少服务器负载,但增加了客户端的计算量。
**用户体验**:可以实现更流畅的过渡效果,如滑动、淡入淡出等。
#### 配置权限和跳转示例:
在HTML中嵌入JavaScript实现跳转:
“`html
“`
这段代码会导致当前页面跳转到`newpage.html`。
### 对比表格
| 特性 | 服务器跳转 | 客户端跳转 |
||||
| 控制权 | 服务器 | 客户端 |
| URL变化 | 是 | 可变 |
| SEO友好度 | 高 | 低 |
| 数据传输 | 可通过URL或服务器会话 | 主要通过AJAX或隐藏的表单提交 |
| 性能开销 | 较高(服务器处理) | 较低(客户端处理) |
| 用户体验 | 一般(直接跳转) | 较好(可实现平滑过渡) |
| 安全 | 较安全(服务器可控) | 较不安全(易受XSS攻击等) |
| 兼容性 | 好(无需额外支持) | 取决于客户端对JavaScript的支持 |
### 相关问题与解答
**Q1: 为什么说客户端跳转对SEO不友好?
A1: 因为搜索引擎的爬虫通常不会执行JavaScript或者对AJAX内容索引能力有限,这意味着通过客户端跳转的内容可能不会被搜索引擎正确索引,从而影响网站的搜索排名。
**Q2: 如何提高客户端跳转的SEO表现?
A2: 可以通过服务器端渲染(SSR)技术使得内容在服务器端生成并提供给搜索引擎爬虫,同时使用客户端跳转为用户提供动态交互体验,合理使用meta标签和确保网站有sitemap也有助于改善SEO。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复