
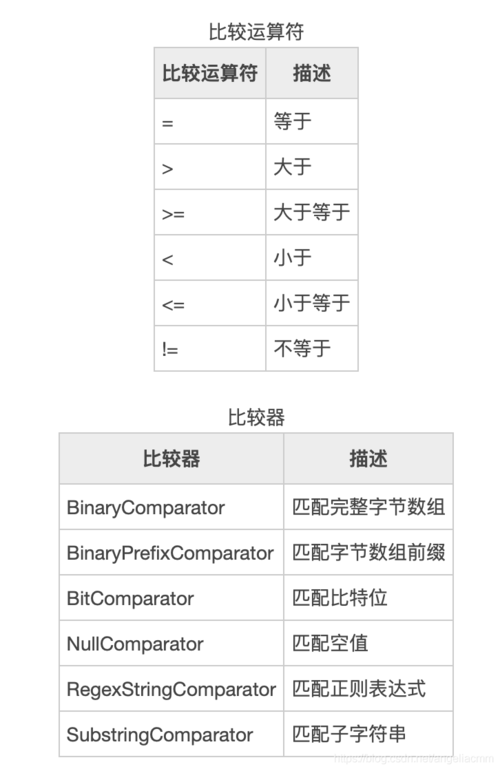
使用Filter过滤器读取HBase表数据

(图片来源网络,侵删)
简介
HBase是一个分布式的、面向列的NoSQL数据库,用于存储大规模的结构化数据,在HBase中,可以使用Filter过滤器来筛选和读取特定的行数据,本文将介绍如何使用Filter过滤器读取HBase表数据。
Filter过滤器的使用
1、创建Filter对象
创建一个实现了org.apache.hadoop.hbase.filter.Filter接口的类。
实现Filter接口的过滤条件方法,boolean filter(Row row)。
2、设置过滤器
使用HTable的setFilter()方法设置过滤器。
将创建的Filter对象作为参数传递给setFilter()方法。
3、执行扫描操作

(图片来源网络,侵删)
使用HTable的getScanner()方法获取一个扫描器对象。
调用扫描器对象的next()方法遍历符合条件的行数据。
示例代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.*;
public class HBaseFilterExample {
public static void main(String[] args) throws Exception {
// 创建HBase配置对象
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "localhost"); // 设置ZooKeeper地址
conf.set("hbase.zookeeper.property.clientPort", "2181"); // 设置ZooKeeper端口号
// 创建连接对象
Connection connection = ConnectionFactory.createConnection(conf);
// 获取表对象
TableName tableName = TableName.valueOf("test_table"); // 替换为实际表名
Table table = connection.getTable(tableName);
// 创建过滤器对象
Filter filter = new FirstKeyOnlyFilter(); // 只返回每行的第一个键值对
// 设置过滤器
table.setFilter(filter);
// 执行扫描操作并遍历结果集
ResultScanner scanner = table.getScanner(new Scan());
for (Result result : scanner) {
// 处理每一行的数据,result表示一行数据的对象
byte[] rowKey = result.getRow(); // 获取行键值
byte[] family = result.getFamily(); // 获取列族名
byte[] qualifier = result.getQualifier(); // 获取列名
byte[] value = result.getValue(family, qualifier); // 获取列的值
System.out.println("Row Key: " + Bytes.toString(rowKey)); // 打印行键值
System.out.println("Family: " + Bytes.toString(family)); // 打印列族名
System.out.println("Qualifier: " + Bytes.toString(qualifier)); // 打印列名
System.out.println("Value: " + Bytes.toString(value)); // 打印列的值
}
scanner.close(); // 关闭扫描器对象
table.close(); // 关闭表对象
connection.close(); // 关闭连接对象
}
} 示例代码演示了如何使用FirstKeyOnlyFilter过滤器读取HBase表中的数据,只返回每行的第一个键值对,可以根据实际需求自定义过滤器类,实现不同的过滤条件。
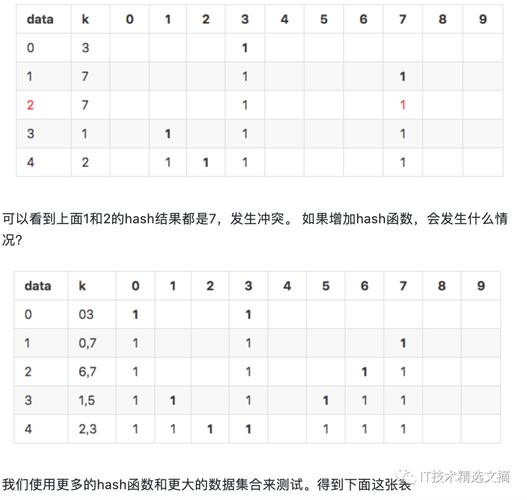
相关问题与解答
问题1:如何根据多个列的条件进行过滤?
解答:可以通过实现MultipleColumnPrefixFilter或ColumnRangeFilter等过滤器类来实现多个列的条件过滤,在实现这些过滤器类时,需要重写相应的过滤条件方法,并在方法内部组合多个列的条件进行判断,最后将创建的过滤器对象设置为表的过滤器即可。
(图片来源网络,侵删)
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复