
程序访问MySQL数据库

1、使用Python的pymysql库连接MySQL数据库:
import pymysql
创建数据库连接
conn = pymysql.connect(host='localhost', user='username', password='password', database='database_name')
创建游标对象
cursor = conn.cursor()
执行SQL查询
sql = "SELECT * FROM table_name"
cursor.execute(sql)
获取查询结果
results = cursor.fetchall()
for row in results:
print(row)
关闭游标和连接
cursor.close()
conn.close() 2、使用Java的JDBC驱动连接MySQL数据库:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class MySQLAccess {
public static void main(String[] args) {
try {
// 加载驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 创建连接
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/database_name", "username", "password");
// 创建语句对象
Statement stmt = conn.createStatement();
// 执行查询
ResultSet rs = stmt.executeQuery("SELECT * FROM table_name");
// 处理结果集
while (rs.next()) {
System.out.println(rs.getString("column_name"));
}
// 关闭资源
rs.close();
stmt.close();
conn.close();
} catch (Exception e) {
e.printStackTrace();
}
}
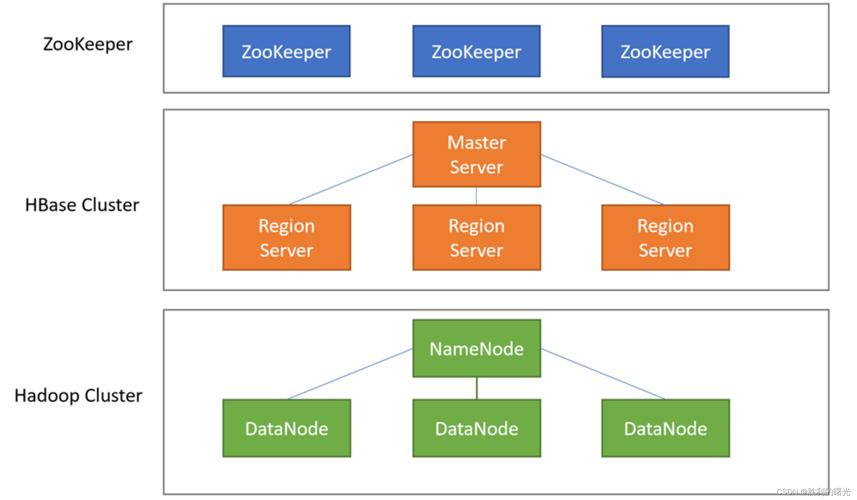
} HBase访问多个ZooKeeper样例程序
1、使用Python的happybase库连接HBase并访问多个ZooKeeper:
import happybase
创建连接池,连接到多个ZooKeeper实例
connection_pool = happybase.ConnectionPool(size=3, host=['zk1:2181', 'zk2:2181', 'zk3:2181'])
从连接池中获取一个连接
with connection_pool.connection() as connection:
# 选择表
table = connection.table('table_name')
# 执行操作,例如获取一行数据
row = table.row('row_key')
print(row) 2、使用Java的org.apache.hadoop.hbase库连接HBase并访问多个ZooKeeper:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseAccess {
public static void main(String[] args) {
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", "zk1,zk2,zk3"); // 设置ZooKeeper集群地址
config.set("hbase.zookeeper.property.clientPort", "2181"); // 设置ZooKeeper端口号
try {
Connection connection = ConnectionFactory.createConnection(config);
Table table = connection.getTable(TableName.valueOf("table_name"));
Get get = new Get(Bytes.toBytes("row_key"));
Result result = table.get(get);
byte[] value = result.getValue(Bytes.toBytes("column_family"), Bytes.toBytes("column_qualifier"));
System.out.println(Bytes.toString(value));
table.close();
connection.close();
} catch (Exception e) {
e.printStackTrace();
}
}
} 相关问题与解答
Q1:如何确保在多线程环境下安全地访问MySQL数据库?
A1: 为了确保在多线程环境下安全地访问MySQL数据库,可以使用以下方法:
使用连接池(如Python的pymysqlpool或Java的HikariCP)来管理数据库连接。
对每个线程分配独立的数据库连接,并在完成操作后关闭连接。
使用事务来确保数据的一致性。
避免长时间持有数据库连接,及时释放资源。
考虑使用锁机制(如乐观锁或悲观锁)来控制并发访问。
Q2:如何在HBase中使用过滤器进行高效的数据检索?
A2: 在HBase中使用过滤器可以有效地减少扫描的数据量,提高检索效率,以下是一些常用的过滤器类型:
SingleColumnValueFilter:基于单列值过滤行。
PrefixFilter:基于行键前缀过滤行。
PageFilter:分页过滤器,用于限制返回的结果数量。
ColumnPrefixFilter:基于列前缀过滤列。
ColumnRangeFilter:基于列范围过滤列。
RowFilter:基于行键过滤行。
CompareFilter:比较过滤器,用于比较特定列的值。
RegexStringComparator:正则表达式比较器,用于匹配字符串模式。
BinaryPrefixComparator:二进制前缀比较器,用于匹配二进制数据。
通过组合这些过滤器,可以实现复杂的查询条件,从而高效地检索数据。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复