
java,import java.sql.Connection;,import java.sql.DriverManager;,import java.sql.SQLException;,,public class HiveConnection {, public static void main(String[] args) {, String url = "jdbc:hive2://:/default";, String user = "";, String password = "";,, try {, Class.forName("org.apache.hive.jdbc.HiveDriver");, Connection connection = DriverManager.getConnection(url, user, password);, System.out.println("Connected to Hive");, connection.close();, } catch (ClassNotFoundException | SQLException e) {, e.printStackTrace();, }, },},`,,请将、、和`替换为您的实际Hive服务器信息。在当今数据驱动的世界中,大数据技术如Hive在处理和分析大规模数据集方面发挥着至关重要的作用,对于企业和开发者而言,能够高效地连接并使用MRS Hive是提升数据处理能力的关键一步,本文将详细介绍如何创建和管理MRS Hive连接的过程,包括必要的配置步骤和一些常见问题的解决方法。
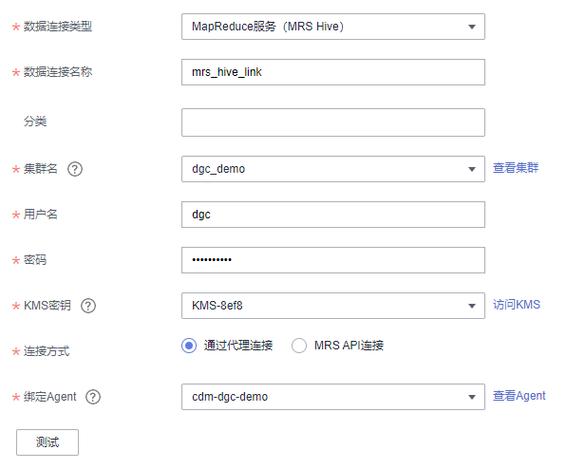

1. MRS Hive连接
MRS Hive是一个基于Hadoop的数据仓库工具,它允许用户通过类SQL的查询语言(HQL)来操作存储在Hadoop分布式文件系统(HDFS)中的数据,创建MRS Hive连接主要涉及配置Hive客户端与Hive服务器的通信。
2. 环境准备
在开始之前,确保以下条件已经满足:
Hadoop集群已正确安装并运行。
Hive服务已在Hadoop集群上正确配置。
网络设置允许从客户端机器到Hadoop集群的通信。
3. 配置步骤
3.1 安装Hive客户端
在客户端机器上安装Hive,这通常涉及到解压缩Hive的安装包并配置环境变量。
3.2 配置Hive连接参数
编辑Hive配置文件(如hivesite.xml),至少需要设置以下参数:
hive.metastore.uris: Hive元数据存储的URI,通常是Hadoop集群中运行Metastore服务的地址。
hive.server2.thrift.bind.host: Hive服务器绑定的主机地址。
hive.server2.thrift.port: Hive服务器监听的端口号。
3.3 测试连接
使用Hive命令行工具或通过编写代码(如使用JDBC)来测试新配置的连接,执行一个简单的查询,如SELECT * FROM tablename LIMIT 10;,以确认连接成功。
4. 连接维护
一旦连接建立,定期检查和维护连接的稳定性是非常重要的,这包括:
监控Hive服务的日志,查找可能的错误或警告信息。
定期更新Hive及相关软件包,以利用最新的功能和安全补丁。
考虑使用连接池和合理的资源管理策略,以优化性能和响应时间。
相关问题与解答
Q1: 如果无法连接到Hive服务器,应如何处理?
A1: 检查网络连接和防火墙设置,确保客户端可以访问Hive服务器,验证Hive服务是否正在运行,并检查Hive配置文件中的参数是否正确,查看Hive和Hadoop的日志文件,寻找可能的错误信息。
Q2: 如何优化Hive查询性能?
A2: 优化Hive查询性能的方法包括:合理设计数据表和分区、使用合适的数据格式(如Parquet)、调整JVM和MapReduce的配置参数、以及使用合适的数据压缩技术,避免使用全表扫描和尽量在过滤条件下推至数据存储层也是提高性能的有效手段。
通过遵循上述步骤和建议,可以有效地创建和管理MRS Hive连接,从而提升数据分析的效率和效果。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复