
分布式缓存更新同步是指在分布式系统中,当某个节点的数据发生变化时,需要将这个变化同步到其他所有节点的缓存中,以保证数据的一致性,这个过程涉及到多个技术点,包括数据同步协议、数据版本控制、数据冲突解决等。
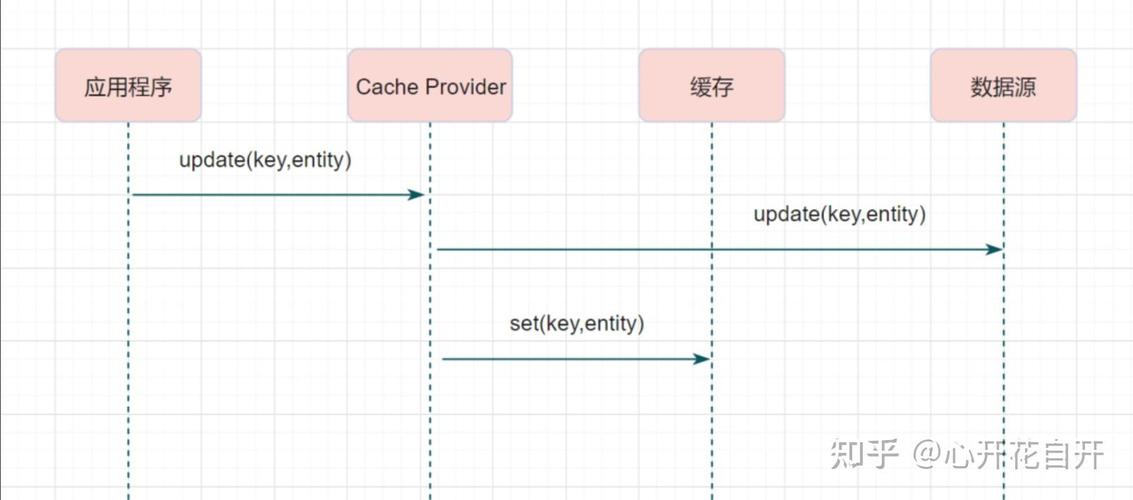

设置分布式缓存
在设置分布式缓存时,我们需要考虑以下几个步骤:
1、选择缓存服务器:我们需要选择一个适合的缓存服务器,如Redis、Memcached等,这些服务器通常都支持分布式部署。
2、配置缓存服务器:我们需要配置缓存服务器,包括设置服务器的网络地址、端口号、密码等,我们还需要配置服务器的持久化策略,以便在服务器重启后能够恢复数据。
3、设计数据结构:我们需要设计缓存中的数据结构,这通常包括键值对的格式、数据的版本信息等。
4、实现数据同步:我们需要实现数据同步的逻辑,这通常包括监听数据变化的机制、数据同步的协议、数据冲突的解决策略等。
以下是一个使用Redis作为缓存服务器,通过发布/订阅模式实现数据同步的例子:
| 步骤 | 操作 | 描述 |
| 1 | 启动Redis服务器 | 在每个节点上启动一个Redis服务器实例 |
| 2 | 配置Redis服务器 | 设置服务器的网络地址、端口号、密码等 |
| 3 | 设计数据结构 | 设计键值对的格式、数据的版本信息等 |
| 4 | 实现数据同步 | 通过发布/订阅模式实现数据同步 |
在这个例子中,我们使用了Python的redis库来操作Redis服务器,当我们需要更新数据时,我们调用publish_data_change函数发布数据变化;当我们需要同步数据时,我们调用subscribe_data_change函数订阅数据变化。
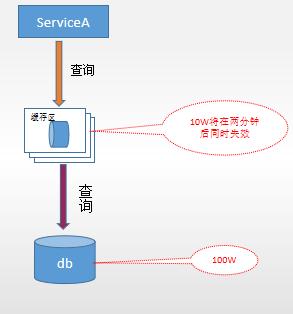
问题与解答
1、Q: 如果数据同步过程中出现了网络故障,我们应该如何保证数据的一致性?
A: 我们可以采用最终一致性模型来处理这种情况,也就是说,当网络恢复正常后,我们再进行数据同步,如果同步过程中发现数据冲突,我们可以根据数据的版本信息来解决冲突。
2、Q: 如果有大量的数据需要同步,我们应该如何优化同步过程?
A: 我们可以采用批量同步的方式来优化同步过程,也就是说,我们将多个数据变化打包成一个消息进行同步,以减少网络传输的次数,我们还可以使用压缩算法来减小消息的大小,进一步提高同步效率。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复