
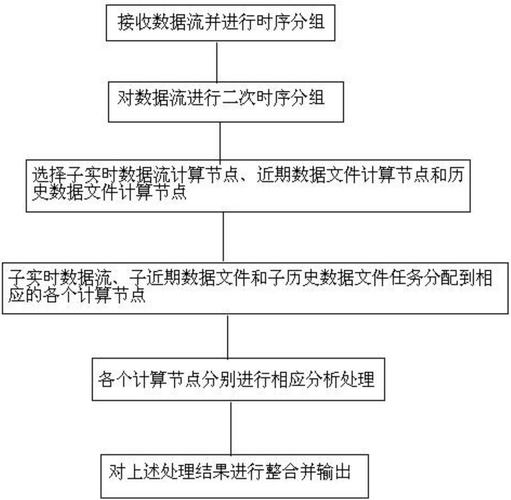
在当今大数据时代,分布式数据流处理已成为信息技术领域的一个热点话题,这种技术主要用于处理高速、大量且持续产生的数据流,其核心在于如何高效、可靠地处理和分析这些数据,以支持实时决策和数据分析,下面将深入探讨分布式数据流的相关内容:

1、定义与特点
基本定义:分布式数据流处理是指在多个计算节点上协同进行连续到达的数据流的处理与分析,这种方法适用于需要快速响应和处理大量动态数据的场景。
主要特点:包括高吞吐量、低延迟处理、可扩展性和高可用性,这些特征确保了分布式数据流处理可以在不同的应用场景中发挥出最大的效能。
2、核心组件
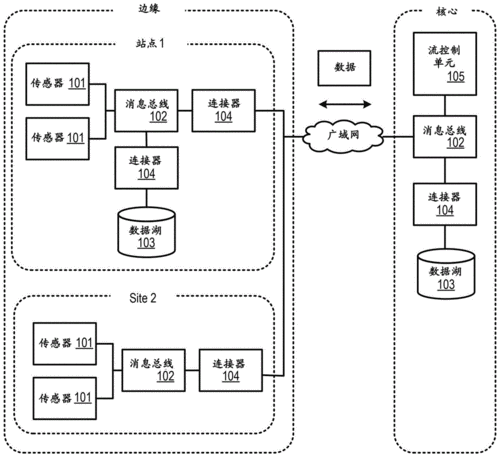
协调机制:例如使用Zookeeper等工具来实现集群中各节点的协调和同步,保证数据处理的一致性和系统的整体稳定性。
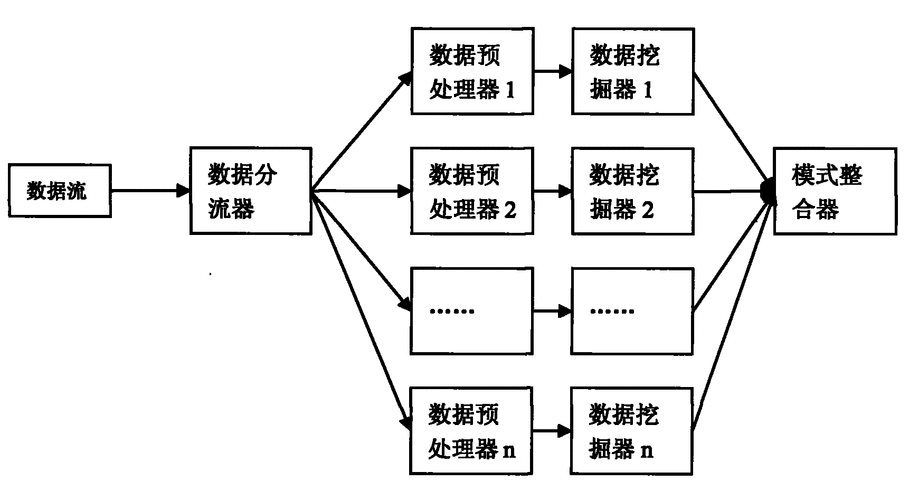
数据处理:通过分散收集机制实现数据的分区和融合,确保数据可以在不同处理单元间有效传输并按照需求进行聚合或分发。
3、关键技术
流平台:如Apache Kafka,这是一个开源的分布式事件流平台,能够处理高吞吐量的数据流,并保证极低的延迟,使其成为实时数据处理的理想选择。
计算框架:Apache Flink是一个优秀的分布式流计算框架,它支持有状态的计算和事件驱动的应用,非常适合用于处理无边界和有边界的数据流。
4、处理模型
实时处理:分布式数据流处理能够实现对数据的实时处理,这对于需要即时反应的应用场景至关重要,如金融交易、在线推荐系统等。
批量处理:现代分布式数据流处理框架如Flink支持批流一体的数据处理模式,这意味着同样的技术栈可以处理实时数据流以及批量数据,提高了资源的利用率和技术的通用性。
5、应用案例
行业应用:分布式数据流处理广泛应用于金融、电商、社交网络、物联网等多个领域,用于处理如交易数据、用户行为日志、设备信号等不同类型的实时数据流。
具体实例:在电商平台中,通过实时分析用户行为数据流,可以实现个性化的商品推荐,提升用户体验和平台的转化率。
可以得出分布式数据流处理不仅涉及复杂的技术挑战,也提供了巨大的商业价值,这种技术正逐渐成为各类组织在数据驱动决策过程中不可或缺的一部分,随着技术的不断发展和应用的深化,分布式数据流处理的效率和普及度将持续提升,为更多领域带来革新。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复