
Fieldaware Factorization Machine,简称FFM)是一种进阶版本的因式分解机(Factorization Machine, FM)算法,它在机器学习领域中广泛应用于稀疏数据的建模任务,如推荐系统和广告点击率预测等场景,FFM通过引入字段(field)的概念来优化标准FM模型,在处理大规模稀疏数据时表现出更好的性能和灵活性,下面将详细探讨FFM在机器学习中的端到端应用场景:

1、数据预处理
原始数据输入:FFM模型需要从原始数据开始处理,这通常包括各种用户行为数据、物品属性数据等。
特征工程:进行合适的特征工程是机器学习任务的关键步骤之一,在FFM模型中,特征工程包括特征选择、特征转换等,以适应FFM对输入特征的需求。
2、模型训练与调优
训练过程:FFM模型的训练涉及到超参数的调整,如正则化项、学习率等,以及训练算法的选择(如随机梯度下降法SGD)来优化模型的性能。
模型验证:使用交叉验证等技术来评估模型在独立数据集上的表现,确保模型具有良好的泛化能力。
3、模型部署与应用
部署方式:训练好的FFM模型可以部署为在线或离线服务,根据实际业务需求进行实时或批量的数据预测。
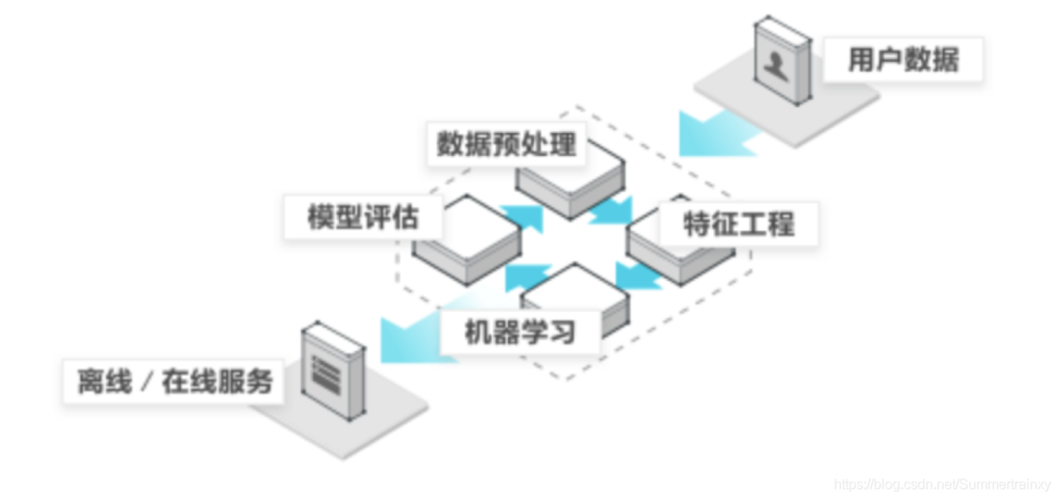
实际应用:在推荐系统中,FFM可用于计算用户与物品之间的相互作用,从而实现个性化推荐;在广告行业,FFM能预测广告的点击率,帮助优化广告投放策略。
4、性能监控与优化
监控指标:关注模型在实际运行中的性能,如准确率、召回率、F1分数等,以及模型响应时间和系统负载等。
持续优化:根据监控反馈调整模型参数或更新训练数据,以应对可能的数据漂移或模型退化问题。
5、数据标注与质量控制
人工标注:在一些应用中,尤其是监督学习任务,需要人工对数据进行标注,以确保训练数据的准确性。
质量控制:定期检查和清理数据,保证数据质量,避免错误数据影响模型性能。
6、技术与方法论演进
创新集成:结合深度学习等先进技术,FFM模型的潜在变体或改进版本可以尝试解决更复杂的问题。
方法论更新:随着机器学习理论和实践的发展,FFM的应用方法和技术也在不断更新,需要持续学习最新的研究成果。
在了解以上内容后,以下还有一些其他建议:
当数据集具有高度稀疏性时,FFM相比其他模型更能有效地捕捉特征间的交互关系。
FFM在处理大规模数据时,可以通过分布式计算实现高效的模型训练和预测。
在实际应用中,应考虑模型的解释性和操作的简便性,以便更好地在实际业务中落地。
FFM作为一种高效的机器学习算法,适用于多种端到端的学习场景,特别是在推荐系统和广告领域表现优异,从数据预处理到模型训练、部署及监控,每一个环节都是优化和应用FFM模型的关键步骤。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复