
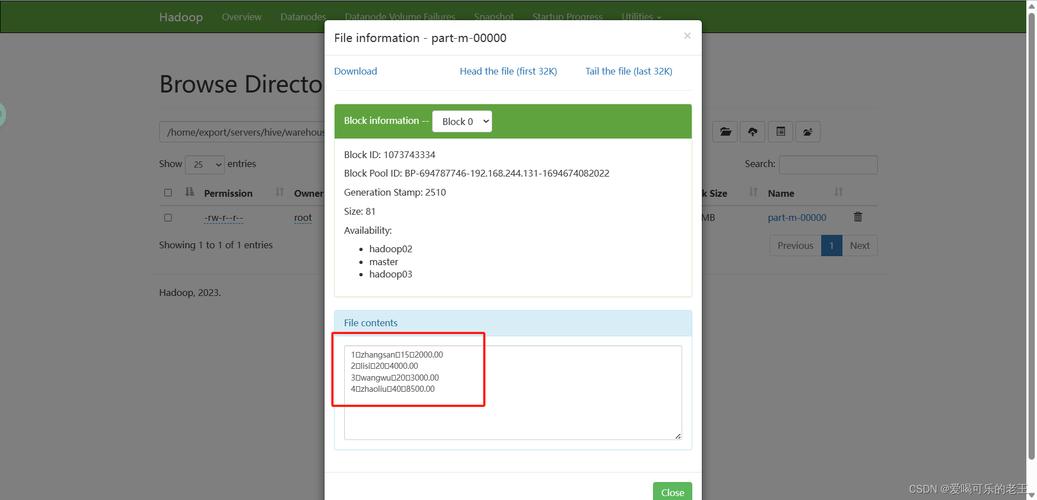
bash,mysqldump u 用户名 p compatible=csv fieldsenclosedby='"' fieldsterminatedby=',' tab=/path/to/output/directory 数据库名 表名,`,,2. 将数据导入到Hive:,,`sql,CREATE EXTERNAL TABLE IF NOT EXISTS hive_table_name,(column1 data_type1, column2 data_type2, ...),ROW FORMAT DELIMITED,FIELDS TERMINATED BY ',',LINES TERMINATED BY ',',STORED AS TEXTFILE,LOCATION '/path/to/hive/warehouse/directory/hive_table_name';,`,,3. 将导出的CSV文件上传到HDFS:,,`bash,hadoop fs put /path/to/output/directory/table_name.txt /path/to/hive/warehouse/directory/hive_table_name,`,,4. 在Hive中加载数据:,,`sql,LOAD DATA INPATH '/path/to/hive/warehouse/directory/hive_table_name' INTO TABLE hive_table_name;,“从MySQL数据库导出数据

使用命令行工具进行数据导出
mysqldump 导出数据
介绍:mysqldump是MySQL提供的备份工具,可将数据库或表的数据导出为SQL脚本文件。
导出整个数据库:使用示例命令mysqldump u [用户名] p [数据库名] > [导出文件路径].sql,可以导出整个数据库(如example_db)到一个.sql文件中。
导出特定表:若要导出特定表,可指定表名,使用类似命令结构,仅改变数据库名和表名的参数值[^1.1.2^]。
权限设置:确保在运行mysqldump命令时,用户具有足够的权限访问指定的数据库及表。
使用图形化工具导出
优势:图形化工具如MySQL Workbench、phpMyAdmin等提供了用户友好的界面,简化了数据导出的操作。
操作步骤:一般通过选择数据库、表以及导出格式等选项后,即可生成.sql或其他格式的导出文件。
特点:适合不熟悉命令行操作的用户,但可能在处理大数据量时存在性能瓶颈。
导入数据到MySQL数据库
使用mysql命令行客户端:mysql命令行客户端可以执行SQL脚本文件,用于将数据导入到MySQL数据库中,使用命令结构mysql u [用户名] p[数据库名] < [导入文件路径].sql 来导入数据。
注意数据格式:导入数据前需确保数据格式与目标数据库结构相匹配,避免因格式错误导致导入失败。
检查字符集编码:导入过程中要注意文件的字符集编码与数据库字符集是否一致,必要时需进行转换以避免乱码问题。
使用编程接口进行数据导入导出
API调用:许多编程语言提供MySQL的API,可以通过几行代码实现数据的导入导出。
灵活性高:编程接口通常提供更多的灵活性,可以自定义复杂的逻辑,如数据转换、清洗等。
安全性考虑:使用编程接口时,应特别注意SQL注入等安全问题,确保代码的安全性。
使用第三方工具
特色功能:一些第三方工具如HeidiSQL、DataGrip等提供了额外的功能,如数据比较、同步等。
易于管理:这些工具往往拥有更加直观的用户界面,使得数据库的管理更加高效。
兼容性问题:在选择第三方工具时,需要考虑其对不同版本MySQL的兼容性。
实际应用案例
网站备份:定期使用mysqldump导出网站数据库作为备份,保障数据安全。
开发环境准备:在开发新功能前,导出生产环境的数据库到开发环境,确保测试环境的数据的一致性。
数据迁移:在项目升级或服务器迁移时,通过导出和导入数据,实现无缝数据迁移。
注意事项与常见问题
数据大小:对于大型数据库的导出导入,应考虑分批次进行,防止一次性操作导致的内存溢出或长时间运行。
安全性:在导出导入数据时,应注意保护敏感信息,避免泄露。
性能影响:尽量在业务低峰期进行数据库的导出导入操作,减少对正常业务的影响。
导入导出Hive数据库
Hive数据导入方法
从本地文件系统导入数据
LOAD DATA LOCAL:此语句用于从本地文件系统加载数据到Hive表中,使用命令LOAD DATA LOCAL INPATH 'local_path' [OVERWRITE] INTO TABLE tablename; 可以将本地文件导入到指定的Hive表中。
注意文件格式:Hive支持不同的文件格式,如CSV、TSV等,需要根据实际的文件格式设置合适的字段分隔符和行格式。
OVERWRITE关键字:该关键字表示覆盖已有数据,如果不希望覆盖原有数据,则不使用此关键字。
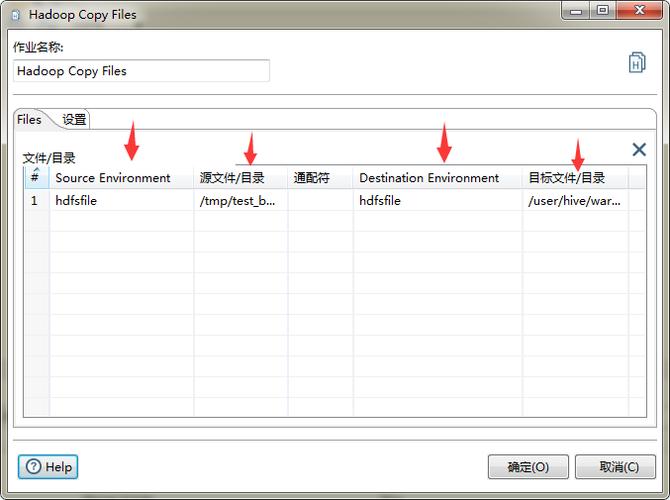
从HDFS导入数据
LOAD DATA:当数据已在HDFS上时,可直接从HDFS加载数据到Hive表,用法类似于本地文件系统,但不需要使用LOCAL关键字。
HDFS路径:指定HDFS上的路径作为数据源,确保Hive有权限访问该路径。
分区表的处理:如果目标表是分区表,可以使用PARTITION子句指定分区名称。
Hive数据导出方法
使用INSERT OVERWRITE导出数据
本地文件系统:使用INSERT OVERWRITE LOCAL DIRECTORY 'local_path' [SELECT ...] 可以将查询结果导出到本地文件系统中。
HDFS:若导出目标为HDFS,则去掉LOCAL关键字,直接指定HDFS路径。
查询导出:这种方式允许对导出的数据进行筛选和处理,只导出满足特定条件的数据。
使用EXPORT命令
简介:Hive还提供了EXPORT命令,用于将表数据导出到HDFS。
用法:EXPORT TABLE tablename [TO path]; 其中tablename是要导出的数据库表名,path是导出的目标路径。
适用场景:适用于快速批量导出表数据,特别是对于分区表的导出非常有用。
注意事项与优化建议
权限与存储:确保Hive用户有权访问导出和导入的路径,无论是本地文件系统还是HDFS。
性能考虑:导入导出大量数据可能会影响Hive和Hadoop集群的性能,应在业务低峰时段执行这些操作。
数据格式匹配:在导入数据前确保数据的格式与Hive表的结构匹配,包括字段类型、序列化方式等。
相关问题与解答
问题1: 如何保证在导出导入过程中数据的一致性?
解答:在开始导出导入操作前,可以先对数据库进行锁定,防止在操作过程中有新的数据写入,使用事务支持的表和InnoDB存储引擎可以保证数据的一致性,操作完成后再解锁。
问题2: 如果遇到大数据量的导出导入任务,有哪些提高效率的方法?
解答:对于大数据集,可以考虑分批次处理,比如按时间、区域等逻辑分割数据,利用并行处理技术,如MapReduce、Spark等,可以提高数据处理的效率,还可以优化硬件配置,如增加内存、使用更快的磁盘等。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复