
在当今数据驱动的商业环境中,非结构化数据管理及其抽取成为了关键议题,本文深入探讨了非结构化数据的定义、挑战、类型与格式,并阐述了如何通过各种技术和工具有效存储、管理及抽取这类数据,释放其潜在价值。

定义与重要性
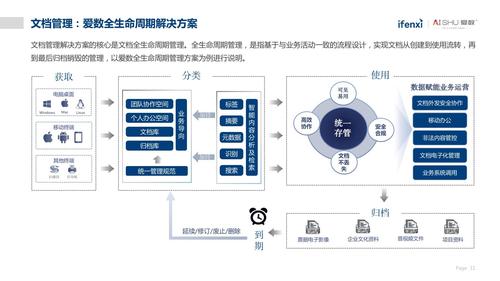
1.1 非结构化数据定义
非结构化数据指的是那些没有预定义模型、不规则或不整齐的数据,如文本文件、图片、视频和音频等,与结构化数据(如数据库中的表格数据)相比,非结构化数据在格式上的不规则性,使其处理和分析更为复杂。
1.2 数据类型与格式
非结构化数据的类型多样,包括但不限于电子邮件、办公文档、网页内容、社交媒体帖子、多媒体文件等,这些数据的格式同样多样化,从文本到图像再到视频,每种格式都对存储和处理方法提出了不同的要求。
1.3 数据价值与挑战
非结构化数据蕴含着巨大的价值,可以提供丰富的洞察力和深层次的观察视角,由于其体量庞大且缺乏结构,如何有效地存储、检索和分析这些数据成为了一项挑战,社交媒体平台每天产生大量的用户生成内容,从中提取有用信息需要高效的数据处理技术。
数据管理技术
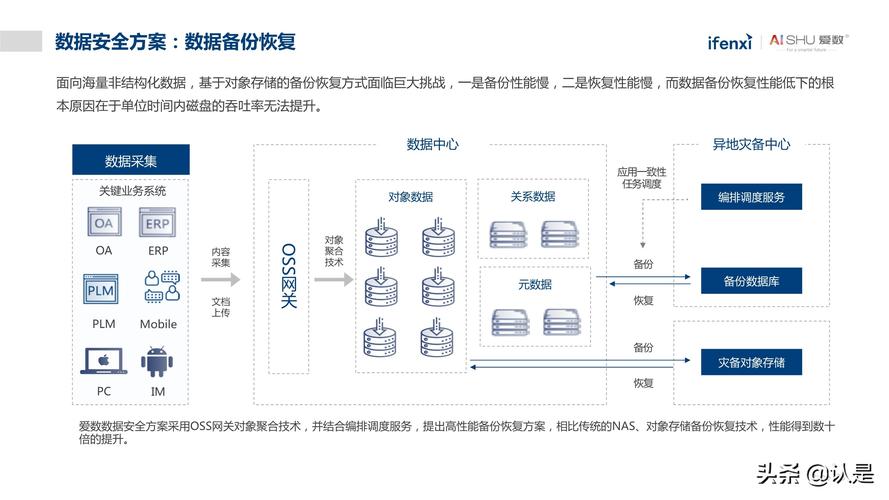
2.1 存储与管理选项
对于非结构化数据,有多种存储和管理方案可供选择,包括传统的文件系统、专用的内容管理系统(CMS)、云存储服务以及大数据平台等,选择合适的存储解决方案需考虑数据的种类、用途和组织的技术架构。
2.2 数据分析工具
市场上提供了多种分析工具来处理非结构化数据,如自然语言处理(NLP)工具、机器学习框架、数据挖掘软件等,这些工具能够帮助组织从非结构化数据中提取洞察,支持决策制定。
2.3 数据质量与治理
非结构化数据的质量管理工作非常关键,它确保了数据的准确性和可用性,数据治理包括数据的清洗、分类、标准化和安全控制等一系列过程,这对于维护数据质量和合规性至关重要。
非结构化数据抽取
3.1 ETL处理
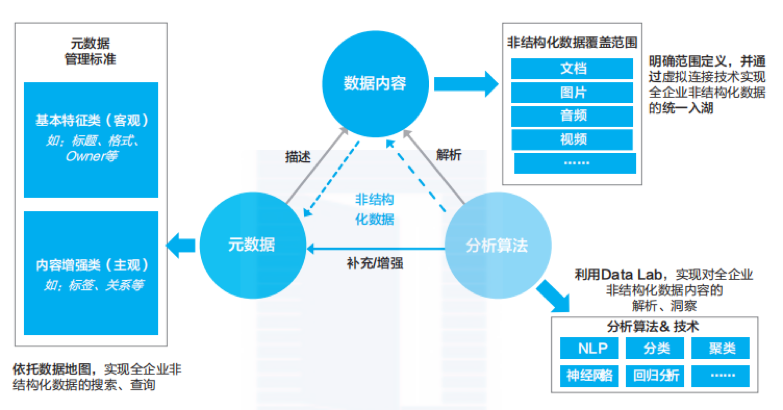
抽取、转换、加载(ETL)是数据处理的一个重要环节,特别是对于非结构化数据,这一过程涉及从源数据中提取信息,转换成结构化形式,然后加载到数据仓库或分析系统中。
3.2 事件抽取
事件抽取是自然语言处理的一个分支,专注于从文本中识别事件及其相关元素,如触发词和论元,这对于理解文本内容,构建知识图谱等应用场景非常重要。
3.3 特征工程
特征工程是从非结构化文本数据中提取有意义特征的过程,这些特征可用于训练机器学习或深度学习模型,有效的特征工程可以显著提高模型的性能和准确性。
上文归纳与建议
非结构化数据管理及抽取是一个复杂但富有成效的领域,关键在于选用合适的技术和工具来应对挑战,组织应投资于先进的数据处理平台,同时培养相关的技术人才,以充分利用非结构化数据的战略价值,随着技术的不断进步,持续关注最新的数据管理和分析趋势也是保持竞争力的必要条件。
相关问题与解答
Q: 如何选择合适的非结构化数据存储方案?
A: 选择存储方案时,要考虑数据的类型、预期的增长量、预算和技术支持等因素,如果数据主要是文本文件,可能需要考虑具有强大搜索功能的CMS;若数据量大且增长快,则云存储服务可能是更好的选择。
Q: 非结构化数据管理面临哪些主要挑战?
A: 主要挑战包括数据的体量大、格式多样、质量不一以及安全问题,缺乏有效的数据处理和分析工具也会增加管理的难度。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复