
Hadoop SQL(也称为 Hive)是一种基于 Hadoop 的分布式数据库,它允许用户使用类似于 SQL 的查询语言对大数据进行操作和分析,Hadoop SQL 是 Apache Hive 项目的一部分,它提供了一种在 Hadoop 集群上执行数据仓库任务的方法。
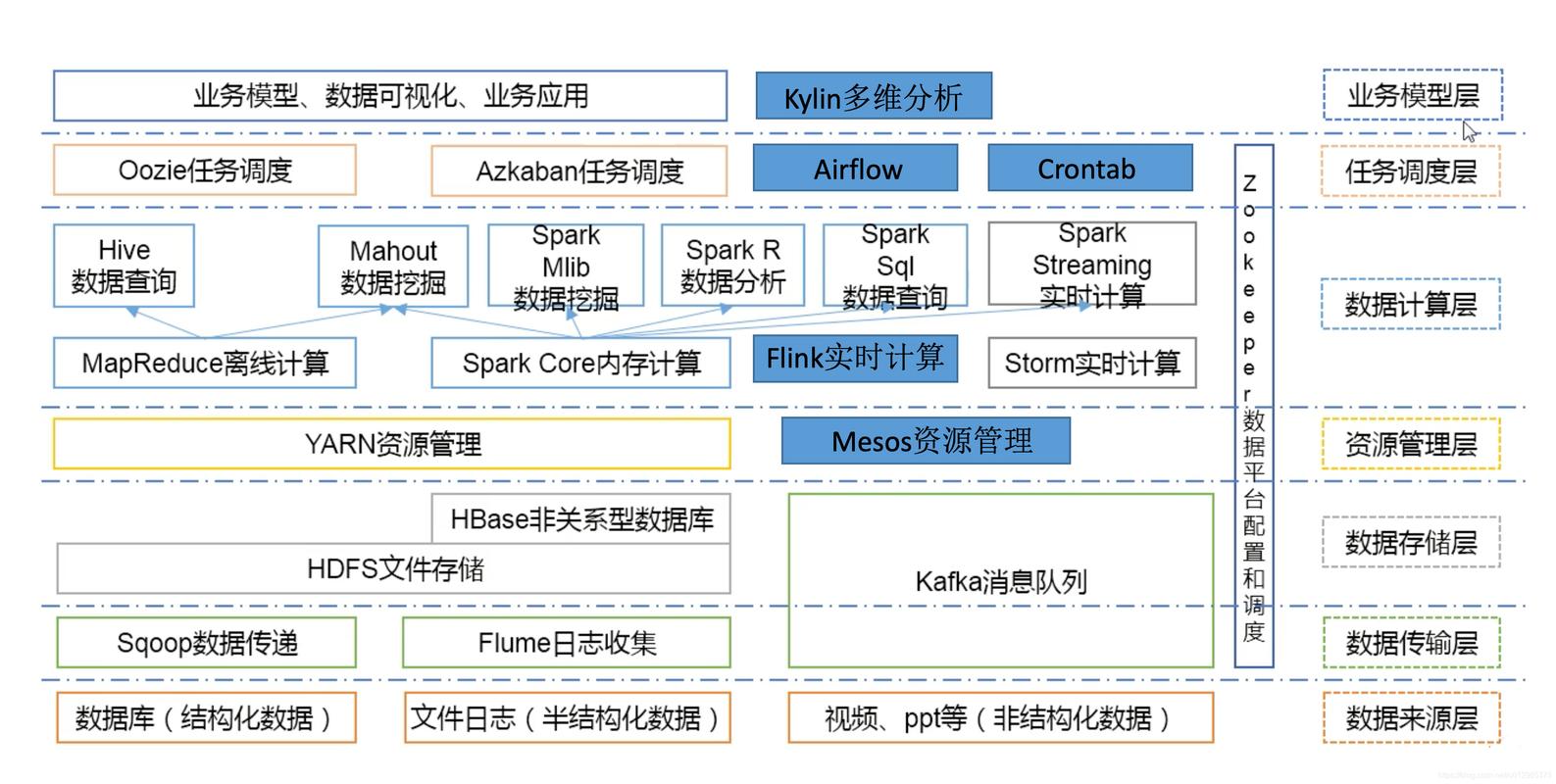

Hadoop SQL 的特点:
1、数据存储: Hadoop SQL 支持多种数据格式,包括文本文件、CSV、JSON、Parquet、ORC 等,并能够处理结构化和非结构化数据。
2、查询语言: 它使用类似 SQL 的查询语言,称为 HiveQL,这使得传统的 SQL 用户可以轻松地编写和理解查询。
3、分布式处理: 利用 Hadoop 的 MapReduce 框架,Hadoop SQL 可以并行处理大规模数据集,提高查询性能。
4、扩展性: 随着数据量的增长,可以通过增加更多的节点来扩展 Hadoop 集群的处理能力。
5、容错性: Hadoop 的设计具有高度的容错性,即使在硬件故障的情况下也能保证数据处理不受影响。
6、成本效益: 由于 Hadoop 运行在普通的硬件上,它通常比传统的数据仓库解决方案更经济。
架构组件:
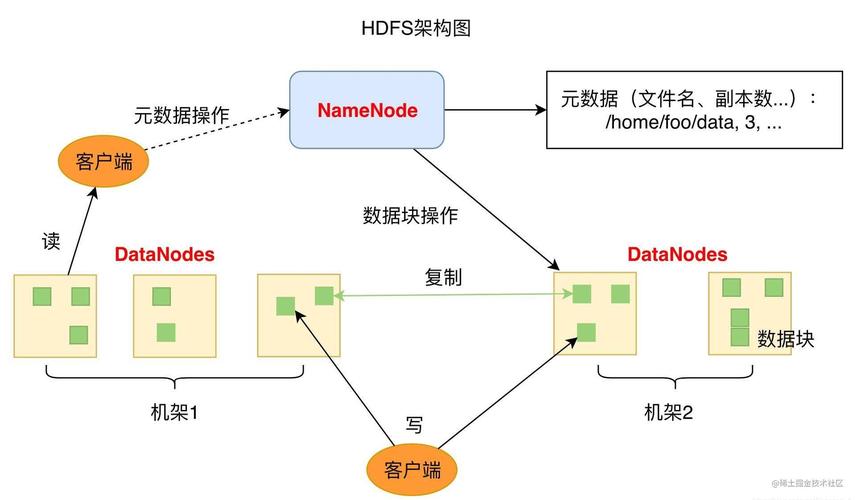
元数据: Hadoop SQL 使用 MySQL 或 PostgreSQL 等数据库来存储元数据,如表名、列名、数据类型等信息。
驱动器: 客户端工具,如命令行界面 (CLI)、JDBC/ODBC 驱动程序或 WebUI,用于提交查询。
编译器: 将 HiveQL 查询编译成 MapReduce 作业。
执行器: 运行 MapReduce 作业来处理查询。
工作流程:
1、用户通过驱动器提交一个 HiveQL 查询。
2、查询编译器解析查询,生成一个或多个 MapReduce 作业。
3、执行器在 Hadoop 集群上运行这些作业。
4、结果返回给用户。
优势与局限性:
优势:
易于使用:对于熟悉 SQL 学习曲线平缓。
可扩展性:能够处理 PB 级别的数据。
容错性:Hadoop 的高容错设计确保了数据的可靠性。
局限性:
延迟:相对于传统数据库,Hadoop SQL 的查询延迟可能较高。
实时处理:不适合需要毫秒级响应时间的实时处理场景。
复杂查询:处理复杂的多阶段查询时性能可能会下降。
应用场景:
日志分析:处理和分析大量的日志数据。
商业智能:提供对大型数据集的洞察,支持决策制定。
数据挖掘:在大规模数据集上运行数据挖掘算法。
相关表格:
| 特性 | 描述 |
| 数据存储 | 支持多种格式,如文本、CSV、JSON、Parquet、ORC 等 |
| 查询语言 | 使用 HiveQL,一种类似 SQL 的语言 |
| 分布式处理 | 利用 MapReduce 并行处理数据 |
| 扩展性 | 可通过增加节点来扩展处理能力 |
| 容错性 | 设计具有高容错性,能容忍硬件故障 |
| 成本效益 | 运行在普通硬件上,成本较低 |
相关问题与解答:
Q1: Hadoop SQL 与传统的关系型数据库管理系统 (RDBMS) 有何不同?
A1: Hadoop SQL 设计用于处理大规模数据集,而传统的 RDBMS 通常面向的是较小规模的、结构化的数据,Hadoop SQL 利用 Hadoop 的分布式存储和 MapReduce 计算框架,可以在多个节点上并行处理数据,从而扩展到非常大的数据集,而 RDBMS 通常在单个服务器或小型集群上运行,且不太适合处理非结构化数据。
Q2: Hadoop SQL 如何处理数据的更新和一致性问题?
A2: Hadoop SQL 并不是为了实时事务处理而设计的,它更适合于批量数据处理,它在处理数据的更新和一致性方面可能不如传统的 RDBMS,通过使用合适的隔离级别和锁机制,以及通过定期的批处理作业来同步数据,可以在 Hadoop SQL 中实现一定程度的数据一致性,对于需要高并发写入和强一致性的场景,可能需要考虑其他技术,如 ACID 兼容的 NoSQL 数据库。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复