
利用MapReduce处理复杂场景涉及对大量数据的高效处理,这通常需要将MapReduce与其他技术如Hadoop集群等进行结合,并深入理解其核心组件和数据处理流程,下面将详细探讨在复杂场景下如何有效利用MapReduce模型:

1、数据准备和预处理
数据清洗:在数据进入Map阶段前,确保数据质量是必要的,这包括去除错误数据、处理缺失值等。
数据格式化:输入数据必须符合Map函数需要的格式,文本数据可能需要分词处理,使之成为可供Map任务处理的键值对格式。
2、Map阶段的优化
并行处理:Map阶段的核心优势在于能够并行处理数据,每个Map任务独立处理一部分数据,互不干扰,提高了数据处理速度。
资源管理:合理分配系统资源,确保每个Map任务都有足够的计算资源,避免成为性能瓶颈。
3、Shuffle and Sort
中间数据组织:MapReduce框架在Map阶段和Reduce阶段之间加入了Shuffle和Sort阶段,用于将Map输出的键值对按照键进行排序和分组,为下一阶段做准备。
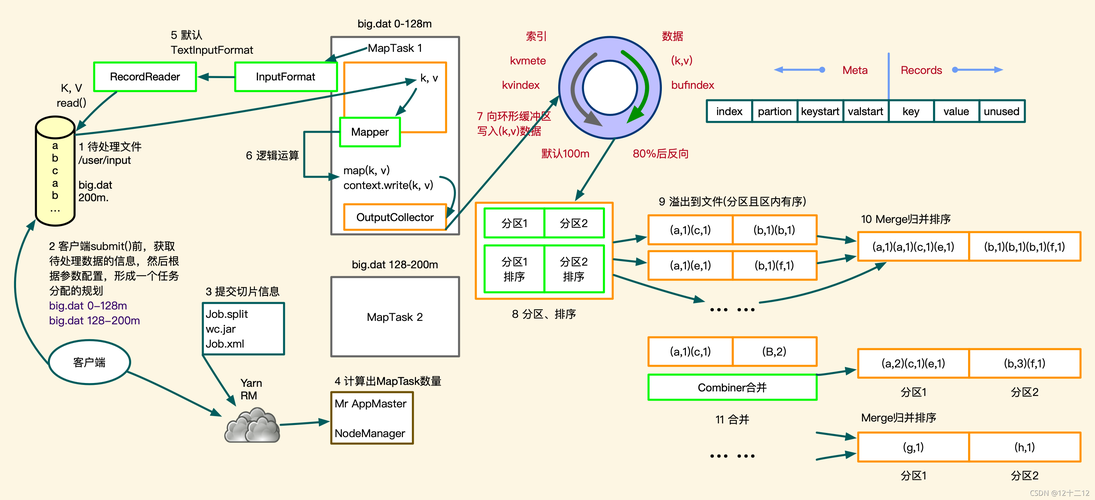
优化数据传输:数据传输是此阶段的性能关键,应尽量减少网络传输量和提高数据传输效率。
4、Reduce阶段的优化
并发处理:与Map任务类似,Reduce任务也可以并行处理数据,每个Reduce任务处理一部分经过Map处理和Shuffle过程的数据。
负载均衡:合理设计Reduce任务的数量和配置,避免某些Reduce任务过载而影响整体性能。
5、数据存储与访问
分布式文件系统:利用分布式文件系统(如HDFS)存储大规模数据集,确保数据的高可用性和容错性。
优化数据访问模式:根据数据处理需求,设计合适的数据存储结构和访问模式,减少I/O开销。
6、容错和可靠性
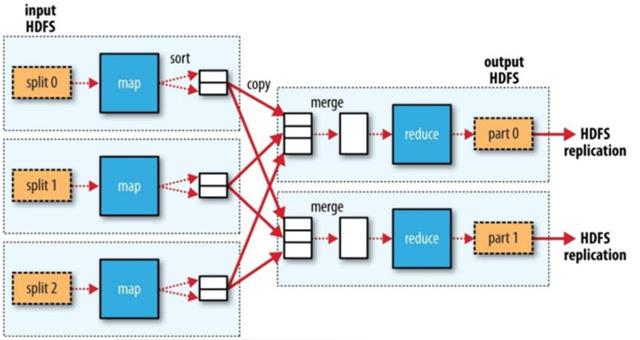
任务失败处理:MapReduce框架需能有效处理任务失败的情况,自动重新调度失败的任务,保证数据处理的准确性和完整性。
数据备份:对重要数据进行备份,以防数据丢失或损坏,影响整个数据处理过程。
7、性能监控和调整
监控工具:使用监控工具跟踪MapReduce作业的运行状态,及时发现性能瓶颈。
动态调整:根据监控结果动态调整资源分配和任务分布,优化作业执行效率。
可以看出MapReduce在处理复杂场景时需要考虑多个方面的因素,从数据预处理到性能监控,每一步都需要精心设计和优化,通过合理利用MapReduce的强大功能,可以有效地处理和分析大规模数据集,支持复杂数据分析和机器学习等多种应用场景。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复