
非结构化数据是指没有固定格式或组织结构的数据,而非结构化抽取则是将这些数据转化为有一定结构和格式的信息,下面将详细探讨非结构化的数据及其抽取方法:

1、非结构化数据的定义与特点
定义:非结构化数据不遵循固定的格式或模式,它们可能是文本、图像、音频、视频等类型的数据。
特点:这类数据的特征在于其多样性和灵活性,它们不像结构化数据那样易于直接通过表格或数据库系统进行查询和分析,常见的非结构化数据包括社交媒体帖子、电子邮件内容、网页抓取结果等。
2、非结构化数据的识别和属性提取
实体识别:实体识别是指在文本中识别出具体的名词或名词短语,如人名、地点、组织机构等,它是信息抽取的基础。
属性提取:属性提取关注的是从一个非结构化的文本中提取出特定的信息,如产品的名称、价格或者某个事件的时间和地点。
3、非结构化数据抽取的方法
文本信息抽取:文本信息抽取技术涉及从文本中识别出有意义的信息,并将其组织成结构化的形式,如数据库记录或XML文件。
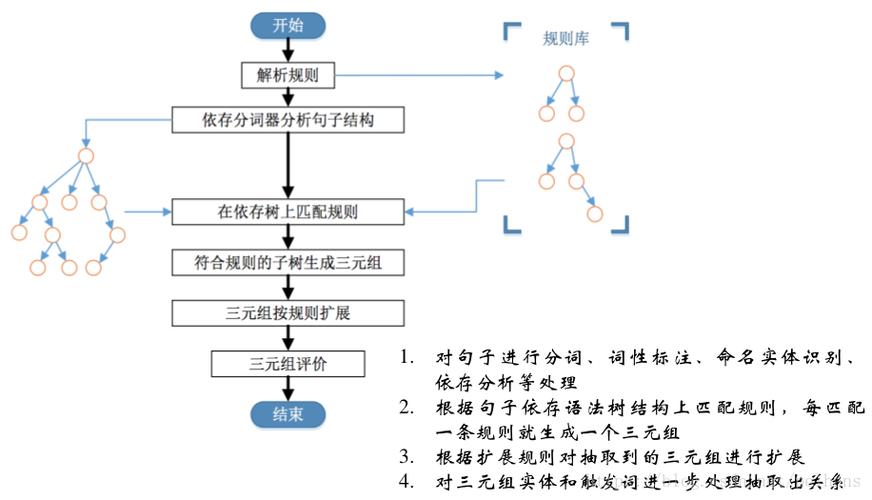
关系抽取:关系抽取是信息抽取的一个分支,它的目标是识别文本中实体之间的语义关系,如“公司A收购了公司B”的交易关系。
4、非结构化数据抽取的实践方法
基于规则的抽取:使用预定义的规则从文本中匹配和提取信息,这种方法简单但需要针对不同的文本结构定制规则。
机器学习抽取:通过训练机器学习模型来自动识别和抽取文本中的信息,这要求有足够的标注数据用于模型训练。
5、非结构化数据抽取的工具与技术
Ratel方法:Ratel是一种基于字典和规则的信息抽取方法,能够处理一定复杂度的文本数据。
JSON和JsonPath:对于半结构化的JSON数据,可以使用JsonPath表达式来提取其中的具体数据,这在网站前后端数据交互时十分有用。
6、非结构化数据抽取的挑战与发展
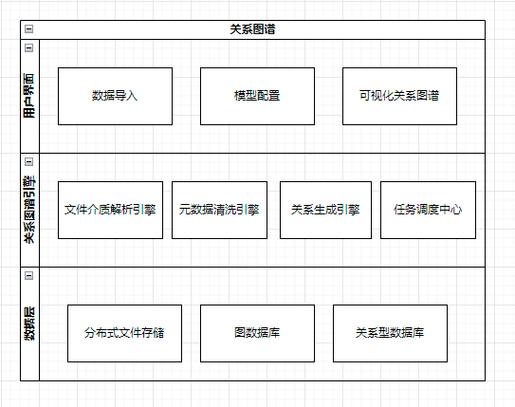
挑战:非结构化数据的不规则性带来了抽取的准确性和全面性问题,同时大数据量的处理也对性能提出了高要求。
发展:随着人工智能和自然语言处理技术的发展,非结构化数据抽取的准确性和自动化水平有望得到显著提升。
非结构化数据虽然处理起来具有一定的难度,但其包含了大量有价值的信息,通过合理的抽取方法,可以极大地扩展人们对数据的认识和应用。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复