
在分布式数据存储系统的构建过程中,配置底层存储系统是一个关键步骤,关系到整个系统的可靠性、可用性和性能,本文将深入探讨分布式数据存储系统中底层存储系统的配置要点,并以HDFS(Hadoop Distributed File System)为例进行详细分析。
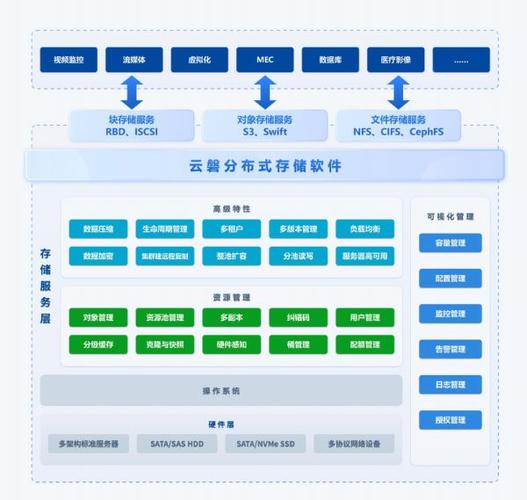

核心架构组成
HDFS是Hadoop的底层分布式存储系统,其设计目标是为了处理大规模数据集的存储需求,HDFS采用主从架构模型,主要包括NameNode和DataNode两个组件。
NameNode:负责管理文件系统的命名空间,维护系统树及整棵树内所有的文件和目录,它还记录着每个文件中各个块所在的数据节点的位置信息,但并不持久化存储这些信息,而是在每次系统启动时重建这些信息。
DataNode:负责在所在服务器上存储和管理数据块(block),并执行数据块的读写操作,每个文件被分割成若干个数据块,存放在不同的DataNode中,每个DataNode保存了所在机器上的数据块元数据信息,并周期性地将所有数据块列表发送给NameNode。
分布式可靠性保障机制
为了保证数据的可靠性和高可用性,HDFS采用了副本机制,即将每个文件的数据块复制到多个DataNode中,默认情况下,每个数据块会有3个副本,分布在不同的机架或数据中心以提升容灾能力。
心跳检测:NameNode周期性地从每个DataNode接收心跳信号,同时通过心跳返回的信息来收集DataNode的状态,如果NameNode在一定时间内没有收到某个DataNode的心跳,则会标记该DataNode为“死亡”,不再向其发送新的I/O请求,并开始复制其上的数据块到其他DataNode。
数据块检查:为了确保数据的完整性,HDFS使用校验和的方法,每个文件的数据块在写入时都会计算校验和并保存,读取时再次计算并与保存的校验和比对,从而确保数据的准确性。
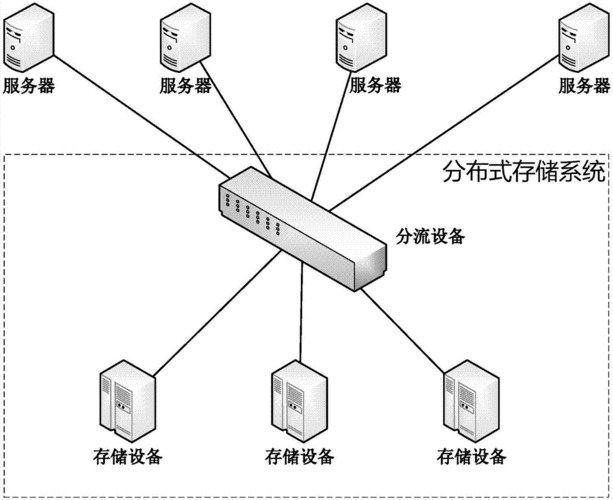
故障恢复:当NameNode发生故障时,可以采用Secondary NameNode或High Availability(HA)机制进行故障恢复,保证服务的持续性。
配置要点
在配置底层存储系统时,需要考虑以下几个方面:
1、硬件选择:根据实际业务需求选择适合的硬件设备,包括服务器、网络设备等,考虑到成本和性能的平衡,通常采用性价比较高的PC服务器。
2、网络规划:确保高速且稳定的网络连接,考虑数据中心内部以及跨数据中心的网络布局,以减少因网络问题导致的数据传输延迟或丢失。
3、数据分片与副本策略:合理设置数据分片大小和副本数量,既要考虑存储成本,也要保证数据可靠性和访问效率。
4、故障检测与恢复:配置有效的故障检测机制,如心跳检测,并预设故障恢复流程,如副本重新分配策略,确保系统能够自动应对硬件故障等情况。
实际应用中的考量因素
在设计和部署分布式数据存储系统时,除了上述技术细节外,还需考虑以下因素:
扩展性:系统应具备良好的水平扩展能力,支持在不中断服务的情况下增加存储容量和处理能力。
安全性:采取必要的安全措施保护数据不被未授权访问或篡改,如数据加密、访问控制等。
成本控制:综合考虑硬件成本、运维成本和人力资源成本,力求达到成本效益最大化。
配置底层存储系统对于分布式数据存储系统的性能和稳定性至关重要,通过精心设计和优化配置,可以有效提高系统的可靠性、可用性和扩展性,满足不同业务场景下的数据存储和管理需求。
问题与解答
Q1: 如何选择合适的硬件设备来构建分布式存储系统?
A1: 在选择硬件设备时,需要根据具体的业务需求和预算来决定,需要考虑服务器的CPU处理能力、内存大小、磁盘容量和速度、网络接口类型等因素,还要考虑设备的能耗和散热情况,确保系统稳定运行,考虑到分布式存储系统的特点,应优先选择支持高速网络连接的设备,并确保有足够的冗余和备份组件以应对单点故障。
Q2: 如何平衡分布式存储系统的性能和成本?
A2: 平衡性能和成本主要涉及硬件选择、软件配置和系统设计三个方面,在硬件选择上,可以通过采购性价比高的PC服务器而不是专用高端服务器来降低成本,在软件配置上,利用开源软件如Hadoop可以减少软件许可费用,在系统设计上,通过合理的数据分片和副本策略,可以在保证数据可靠性的同时提高存储利用率和访问效率,还可以通过动态资源调配和自动化管理降低运维成本,实现成本与性能的最优平衡。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复