
二分查找是一种在有序数组中查找特定元素的搜索算法,它的基本思想是将目标值与数组中间元素进行比较,如果目标值等于中间元素,则查找成功;如果目标值小于中间元素,则在左半部分继续查找;如果目标值大于中间元素,则在右半部分继续查找,重复这个过程,直到找到目标值或者搜索范围为空。
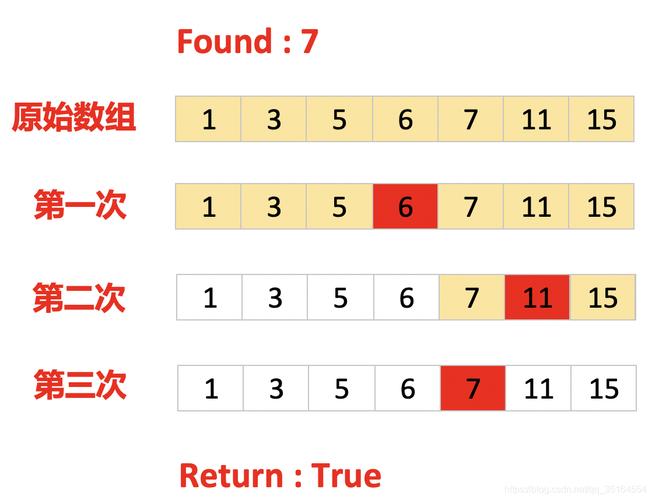

下面是一个使用Python实现的二分查找函数:
def binary_search(arr, x):
low = 0
high = len(arr) 1
mid = 0
while low <= high:
mid = (high + low) // 2
# 如果x存在于中间位置
if arr[mid] < x:
low = mid + 1
# 如果x存在于右半部分
elif arr[mid] > x:
high = mid 1
# x存在于中间位置
else:
return mid
# x不存在于数组中
return 1 接下来是关于k均值聚类(Kmeans clustering)的简要介绍,k均值聚类是一种无监督学习算法,用于将数据集划分为k个簇(cluster),算法的基本步骤如下:
1、随机选择k个数据点作为初始聚类中心(centroids)。
2、将每个数据点分配到最近的聚类中心所在的簇。
3、更新每个簇的聚类中心为该簇内所有数据点的平均值。
4、重复步骤2和3,直到聚类中心不再发生变化或达到最大迭代次数。
下面是一个简单的k均值聚类算法的Python实现:
import numpy as np
from sklearn.cluster import KMeans
def k_means_clustering(data, k):
kmeans = KMeans(n_clusters=k)
kmeans.fit(data)
return kmeans.labels_ 相关问题与解答:

问题1:如何在二分查找中处理重复元素?
答案1:在二分查找中,如果数组中有重复的元素,通常我们可以找到任意一个匹配的元素即可,在上面给出的二分查找函数中,当找到目标值时,它会立即返回中间索引,即使有多个相同的目标值,该函数也会返回其中一个匹配的索引。
问题2:如何优化k均值聚类算法的性能?
答案2:k均值聚类算法的性能可以通过以下几种方式进行优化:
选择合适的初始化方法:不同的初始化方法可能会导致不同的聚类结果,可以使用kmeans++算法来选择初始聚类中心,以加速收敛并提高聚类质量。
调整停止条件:可以设置最大迭代次数或聚类中心变化的阈值作为停止条件,当达到这些条件时,算法会提前终止,从而节省计算资源。
使用近似算法:对于大规模数据集,可以使用近似算法如MiniBatch KMeans,它在每次迭代中使用一部分样本来更新聚类中心,从而减少计算时间。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复