
ETL MapReduce作业概述
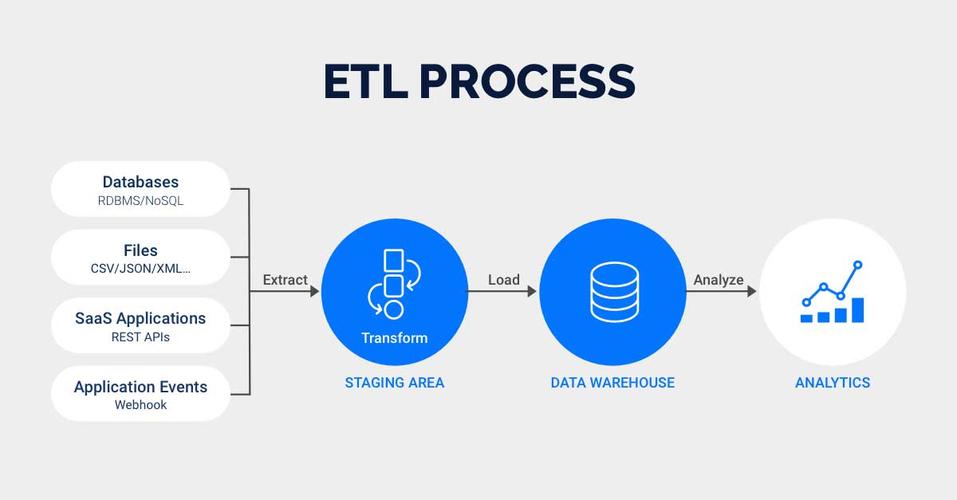

ETL(Extract, Transform, Load)是一种数据处理过程,用于从源系统中提取数据,经过转换后加载到目标系统中,MapReduce是一种编程模型和框架,用于处理和生成大数据集的相关实现,结合ETL与MapReduce可以有效地处理大规模数据的抽取、转换和加载任务。
数据抽取 (Extract)
在Map阶段,系统读取原始数据文件,通常这些数据是分布式存储的,每个Map任务负责处理一部分数据,并将数据解析成键值对。
数据转换 (Transform)
在Map函数中进行初步的数据转换,如过滤、排序等操作,通过Shuffle和Sort阶段将相同键的值聚集在一起,为Reduce阶段做准备。
数据加载 (Load)
在Reduce阶段,执行进一步的转换操作,并将结果输出到最终的目标系统,这可能包括聚合计算、连接操作或简单的数据格式化。
实施步骤
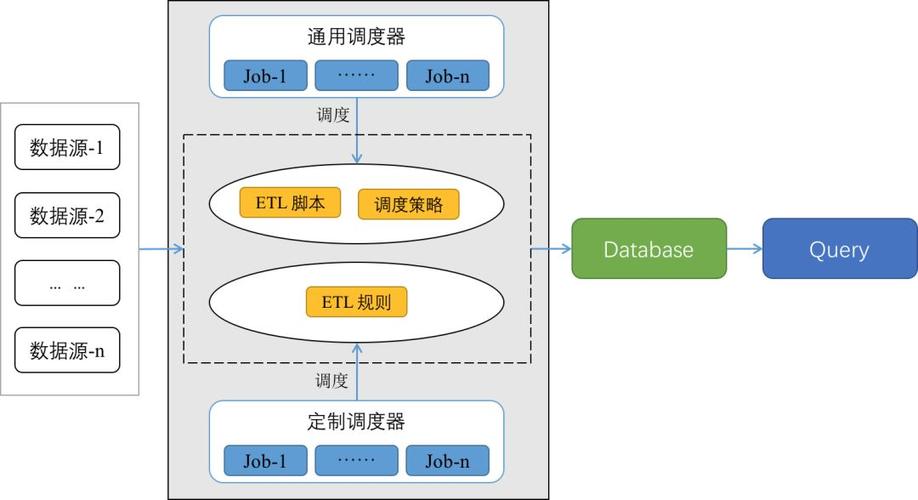
1、定义数据源:确定需要抽取的数据来源,例如文本文件、数据库等。
2、设计Map函数:编写Map函数来处理输入数据,并生成中间键值对。
3、配置Shuffle和Sort:设置系统以正确分配数据给Reduce任务。
4、设计Reduce函数:编写Reduce函数来接收中间数据,并进行最终的转换和输出。
5、配置输出格式:指定输出数据的格式和目标位置。
6、测试和调优:运行ETL作业,监控性能并根据需要调整参数。
注意事项
确保Map和Reduce函数的错误处理机制健全,避免因异常数据导致作业失败。
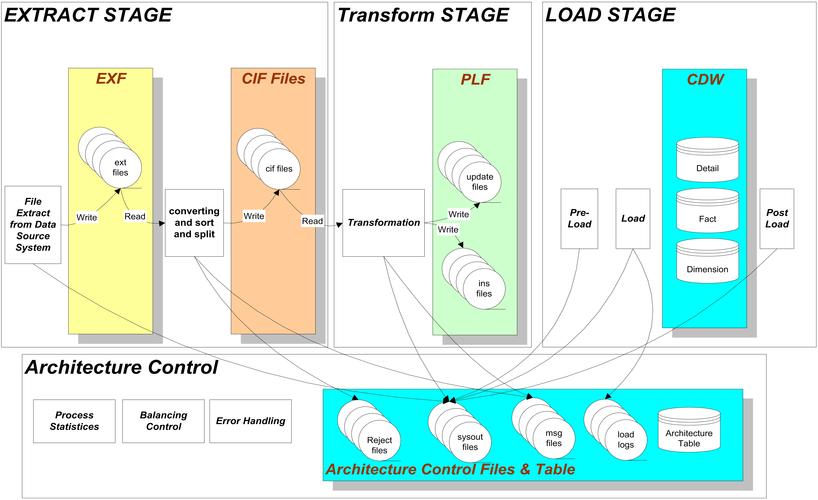
考虑数据局部性,以减少网络传输开销。
优化Shuffle和Sort阶段,以提高整体作业效率。
监控资源使用情况,如内存和磁盘空间,确保作业稳定运行。
相关问题与解答
Q1: ETL MapReduce作业在处理大数据时有哪些优势?
A1: ETL MapReduce作业的优势包括:
易于并行处理:MapReduce框架可以自动分配和管理多个计算任务,充分利用集群的计算能力。
容错性:框架能够处理节点故障,自动重新分配失败的任务。
可扩展性:可以根据数据量和计算需求动态增加或减少计算资源。
适用于非结构化和半结构化数据:MapReduce适合处理大量非标准格式的数据。
Q2: 如何优化ETL MapReduce作业的性能?
A2: 优化ETL MapReduce作业性能的方法包括:
合理设置Map和Reduce的数量,根据数据大小和集群能力进行调整。
优化数据分区,确保数据均匀分布在各个Reduce任务上。
使用压缩技术减少数据传输量和存储空间。
优化Map和Reduce函数的逻辑,避免不必要的计算和数据操作。
监控作业执行,分析瓶颈,根据实际运行情况进行调优。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复