
在当前快速发展的人工智能领域,有效的数据存储和查询变得至关重要,PGVector作为一个高效的向量数据库插件,为PostgreSQL数据库带来了强大的向量搜索能力,支持多种向量计算算法和数据类型,特别适用于AI Embedding的高效存储与查询,将详细介绍pgvector插件的特点、使用方法以及在实际应用中的优势。
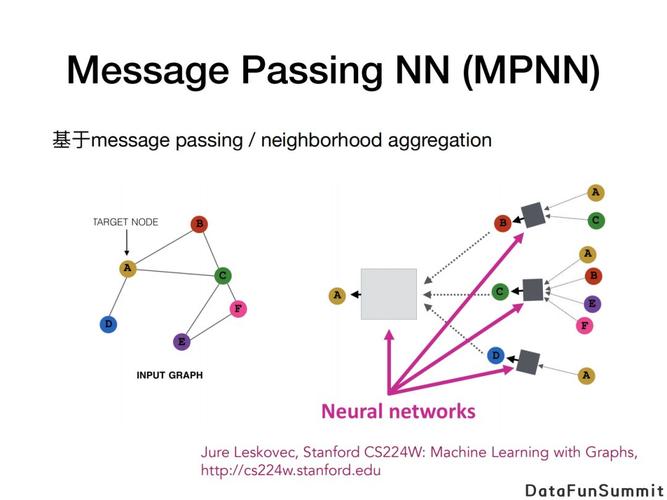

背景与原理
1、背景:随着机器学习和人工智能技术的迅猛发展,对向量数据的支持成为数据库管理系统的一个重要需求,传统的关系型数据库在处理高维度向量数据时存在效率低下的问题,PGVector应运而生,它通过集成至PostgreSQL数据库,扩展了其功能,使其能够有效管理向量数据。
2、原理:PGVector通过实现向量数据的高效编码和索引结构,如倒排索引、KD树等,加快了向量数据的查询速度,它支持精确和近似最近邻搜索(ANN),使得大规模向量数据集的相似度匹配变得可能。
使用方法
1、安装与配置
环境准备:确保PostgreSQL数据库已安装并运行正常。
插件安装:使用PostgreSQL的扩展管理命令CREATE EXTENSION来安装PGVector插件。
2、创建向量表
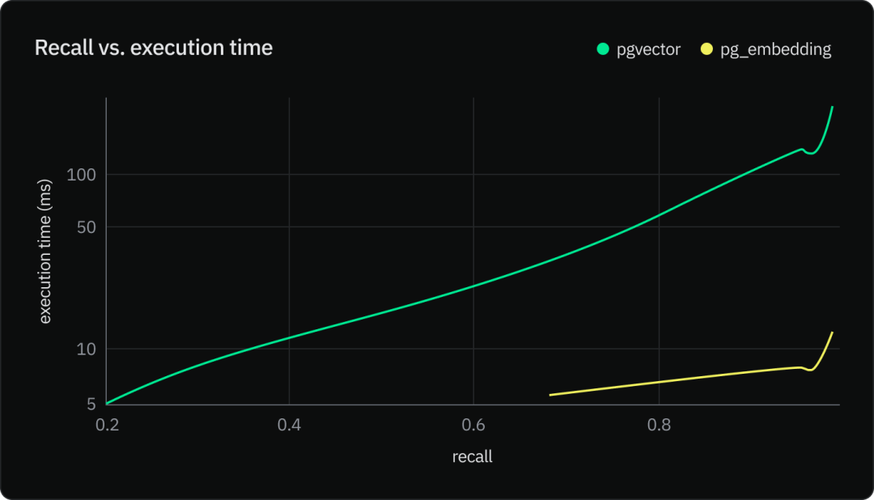
数据类型定义:使用PGVector提供的VECTOR类型来定义表中的向量列。
表创建:通过常规的SQL建表语句创建包含向量列的表。
3、数据操作
插入数据:使用标准的INSERT语句将向量数据插入到向量列中。
查询数据:利用PGVector提供的操作符和函数进行向量数据的查询,包括相似项搜索等。
4、高级查询
相似度搜索:利用内积或欧氏距离等度量方法,查询相似向量。
最近邻搜索:执行精确或近似最近邻搜索,找到最相似的向量集合。
实际应用优势
1、性能提升:与传统的关系型数据库相比,PGVector在处理向量数据时的查询速度更快,特别是在高维数据空间中。
2、多样化的查询方式:支持多种向量计算算法,包括最近邻搜索和相似度匹配,满足不同应用场景的需求。
3、易于集成:作为PostgreSQL的一个插件,PGVector可以轻松地被集成到现有的基于PostgreSQL的应用中,无需更换数据库系统。
相关问题与解答
1、Q: PGVector支持哪些向量计算算法?
A: PGVector支持包括内积、欧氏距离等多种向量计算算法,用于执行相似度匹配和最近邻搜索。
2、Q: 如何保持PGVector中数据的安全性?
A: PGVector继承了PostgreSQL的安全特性,包括访问控制、加密等,确保数据安全性。
PGVector插件为PostgreSQL数据库提供了强大的向量数据处理能力,不仅提高了查询效率,还丰富了数据处理的算法和方法,这使得PGVector成为AI和机器学习项目中处理高维数据的理想选择。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复