
对象存储并行文件系统(Object Storage Parallel File System,OPFS)是一种用于存储和管理大规模数据的文件系统,它采用分布式架构,将数据切分为多个对象,并将这些对象存储在多个服务器上,以实现高并发、高可用和高性能的数据访问。
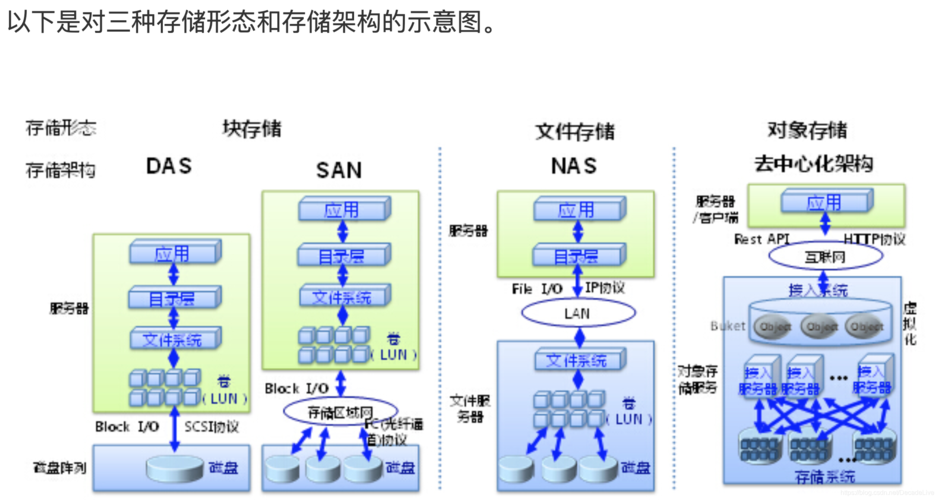

OPFS的特点
1、高并发:OPFS支持多用户同时访问和操作数据,通过并行处理技术提高系统的并发性能。
2、高可用:OPFS采用分布式架构,数据分布在多个服务器上,即使某个服务器出现故障,其他服务器仍能正常提供服务。
3、高性能:OPFS通过数据分片和并行处理技术,提高了数据的读写速度和响应时间。
4、可扩展性:OPFS可以根据需求动态扩展存储容量和计算能力。
5、容错性:OPFS采用数据冗余和校验机制,确保数据的可靠性和一致性。
OPFS的工作原理
1、数据切分:OPFS将数据切分为多个对象,每个对象包含数据内容和元数据。
2、数据分布:OPFS将对象分布在多个服务器上,每个服务器负责存储一部分对象。
3、数据访问:用户通过客户端程序访问OPFS,客户端程序将请求发送到指定的服务器,服务器根据请求查找并返回相应的对象。
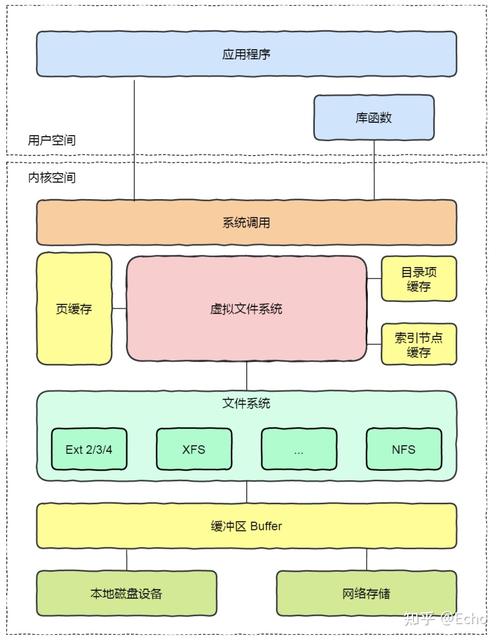
4、数据一致性:OPFS采用一致性哈希算法(Consistent Hashing)将对象映射到服务器,当服务器数量发生变化时,只需重新分配部分对象,而不需要重新分配所有对象,从而保证数据的一致性。
OPFS的应用
1、大数据存储:OPFS适用于存储海量的非结构化数据,如图片、视频、音频等。
2、云存储:OPFS可以作为云存储服务的基础架构,提供高并发、高可用和高性能的存储服务。
分发网络(CDN):OPFS可以将静态资源分布在多个服务器上,提高资源的访问速度和稳定性。
4、备份和恢复:OPFS可以作为数据备份和恢复的解决方案,将数据分布在多个服务器上,提高数据的可靠性和安全性。
相关问题与解答
问题1:OPFS如何实现数据的一致性?
答:OPFS采用一致性哈希算法(Consistent Hashing)将对象映射到服务器,当服务器数量发生变化时,只需重新分配部分对象,而不需要重新分配所有对象,从而保证数据的一致性。
问题2:OPFS如何处理数据的冗余?
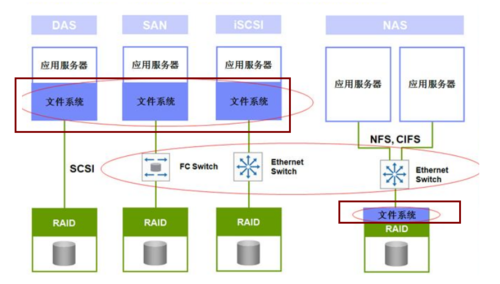
答:OPFS采用数据冗余和校验机制来确保数据的可靠性,每个对象都会在多个服务器上存储多个副本,当某个副本出现错误时,可以通过其他副本进行修复,OPFS还会对数据进行校验,确保数据的一致性和完整性。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复