
导出Hive表/分区数据
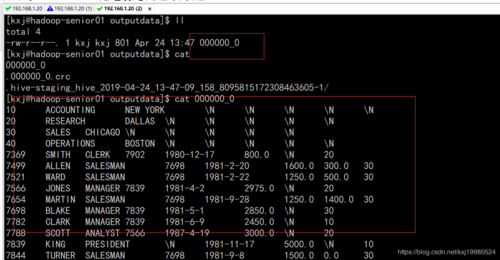

要导出Hive表或分区的数据,可以使用INSERT OVERWRITE命令将查询结果写入到HDFS或其他支持的文件系统中,以下是一些示例:
1、导出整个表的数据:
“`sql
INSERT OVERWRITE LOCAL DIRECTORY ‘/path/to/local/directory’
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘,’
STORED AS TEXTFILE
SELECT * FROM your_table;
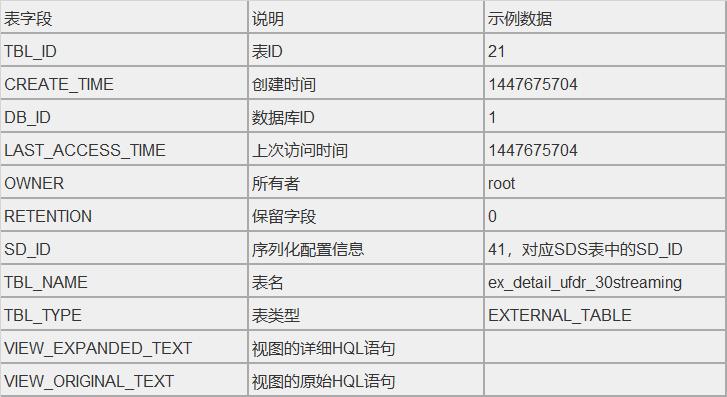
“`
2、导出表的特定分区数据:
“`sql
INSERT OVERWRITE LOCAL DIRECTORY ‘/path/to/local/directory’
PARTITION (partition_column=’value’)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘,’
STORED AS TEXTFILE
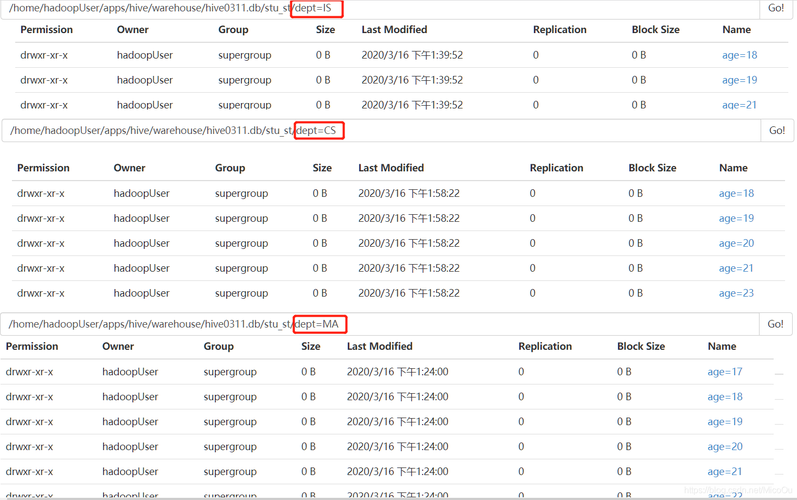
SELECT * FROM your_table;
“`
3、导出表的部分列数据:
“`sql
INSERT OVERWRITE LOCAL DIRECTORY ‘/path/to/local/directory’
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘,’
STORED AS TEXTFILE
SELECT column1, column2 FROM your_table;
“`
导入Hive表/分区数据
要将数据导入到Hive表中,可以使用LOAD DATA命令从HDFS或其他支持的文件系统中读取数据,以下是一些示例:
1、导入整个表的数据:
“`sql
LOAD DATA LOCAL INPATH ‘/path/to/local/datafile’
INTO TABLE your_table;
“`
2、导入表的特定分区数据:
“`sql
LOAD DATA LOCAL INPATH ‘/path/to/local/datafile’
INTO TABLE your_table
PARTITION (partition_column=’value’);
“`
3、导入表的部分列数据:
“`sql
LOAD DATA LOCAL INPATH ‘/path/to/local/datafile’
INTO TABLE your_table (column1, column2);
“`
常见问题与解答:
1、问题: 如何避免在导出和导入过程中出现数据不一致的问题?
答案: 为了避免数据不一致,可以在导出前使用EXPORT命令将表锁定为只读模式,并在导入完成后解锁,这样可以确保在导出和导入过程中不会有其他操作修改表的数据。
2、问题: 如何优化导出和导入的性能?
答案: 为了提高性能,可以考虑以下方法:
使用并行执行:通过设置hive.exec.parallel参数来启用并行执行,可以加快数据的导出和导入速度。
调整HDFS块大小:根据数据的大小和集群的配置,调整HDFS的块大小以获得更好的读写性能。
使用压缩格式:在导出和导入时使用压缩格式(如Gzip、Snappy等)可以减少存储空间并提高数据传输速度。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复