
ETL(Extract, Transform, Load)数据仓库技术是数据集成的核心过程,它负责将数据从源系统提取(Extract),经过必要的转换(Transform),然后加载到目标数据仓库中(Load),在构建和维护数据仓库时,ETL任务(Job)扮演着至关重要的角色。
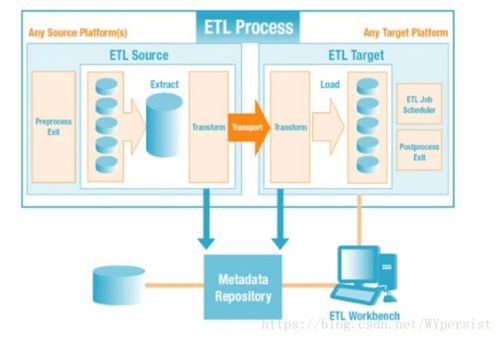

ETL Job的设计和实现
数据抽取(Extract)
源系统识别:确定哪些数据需要被抽取,包括数据库、文件系统等。
连接方式:使用API、直接数据库连接或文件传输等方法连接到源系统。
数据访问频率:设定数据抽取的频率,如实时、每日、每周等。
增量与全量抽取:选择适当的抽取方式以优化性能和资源利用。
数据转换(Transform)
数据清洗:去除重复、错误或不一致的数据。
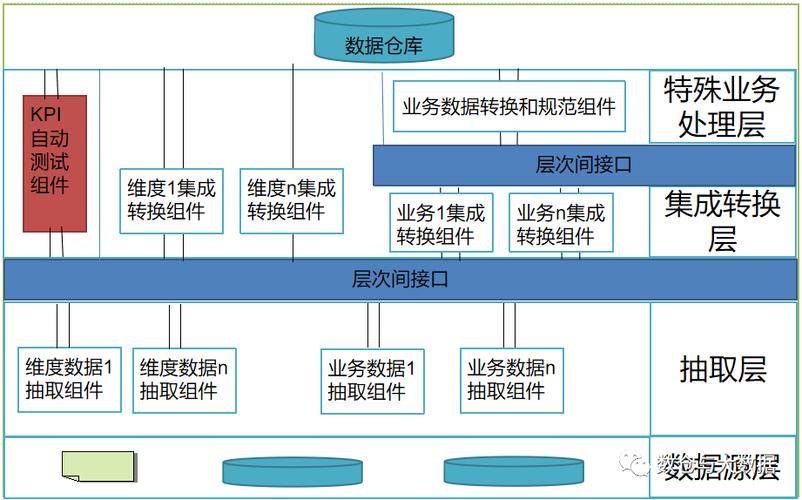
数据整合:合并来自不同源的数据,解决数据冲突。
数据富化:增加额外的信息,如计算字段、编码转换等。
数据聚合:对数据进行汇总处理,生成报告所需的统计信息。
数据加载(Load)
维度表和事实表构建:根据数据仓库的星型或雪花模型设计,创建相应的维度表和事实表。
加载策略:批量加载、缓慢变更维度、快速加载等。
性能优化:索引、分区、并发加载等技术的应用。
数据验证:确保加载的数据准确无误,并与源数据保持一致。
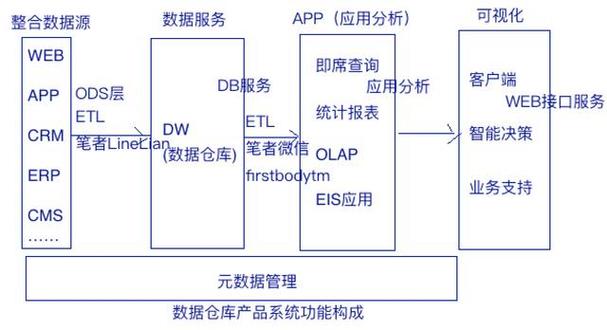
ETL工具和技术
工具选择:商业ETL工具(如Informatica, Talend)或开源工具(如Apache NiFi, Logstash)。
调度和监控:使用ETL工具的内建调度功能或外部调度器(如ControlM, Cron Jobs)。
日志和错误处理:记录ETL过程中的关键事件和错误,便于故障排查和修复。
维护和管理
版本控制:对ETL脚本和程序进行版本管理。
性能监控:定期检查ETL Job的性能,进行必要的调优。
数据质量监控:实施数据质量检查,确保数据的准确性和完整性。
依赖管理和故障恢复:管理作业之间的依赖关系,制定故障恢复计划。
相关问题与解答
问题1: ETL过程中如何处理大数据量?
答案: 处理大数据量时,可以采取以下措施:
使用并行处理来加速数据的抽取、转换和加载过程。
采用增量加载而非全量加载,只处理自上次加载以来发生变化的数据。
在ETL过程中使用高效的数据存储格式,如列式存储,以提高查询性能。
对数据进行分区,以便能够并行处理,并加快数据检索速度。
优化网络传输,例如压缩数据以减少传输时间和带宽需求。
问题2: 如何保证ETL过程的数据一致性?
答案: 保证数据一致性的方法包括:
在ETL设计阶段确立清晰的数据质量标准和一致性规则。
在转换阶段实施数据清洗和验证,确保数据符合预定的质量标准。
利用事务管理确保数据的原子性,即数据要么全部加载成功,要么全部不加载。
在数据加载到目标系统后进行完整性检查,比对源数据和目标数据的差异。
定期进行数据审计,以确保长期的数据一致性和准确性。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复