
分布式日志收集

在现代的软件开发和运维过程中,日志数据是不可或缺的信息源,它对于理解系统运行状态、调试问题以及性能监控都至关重要,随着微服务架构和分布式系统的广泛应用,传统的单一节点日志收集方式已经不再适用,需要更加高效和可扩展的解决方案来应对分散在各个节点上的日志数据,分布式日志收集系统应运而生。
分布式日志收集系统的关键特性
1、集中化管理:将散布在不同服务器或容器中的日志数据汇总到一个中心位置,便于统一管理和分析。
2、高可用性:确保日志数据的收集不会因为单点故障而中断,通常通过冗余部署实现。
3、实时处理:支持实时或近实时的日志数据传输和处理,以满足快速响应的需求。
4、可伸缩性:能够根据系统负载动态调整资源,以处理大量日志数据。
5、容错性:具备良好的错误恢复机制,即使在部分组件失败的情况下也能保证日志数据的完整性。
6、多源支持:能够从不同的日志源(如文本文件、标准输出、网络服务等)收集日志。
分布式日志收集工具
市面上有多种分布式日志收集工具,以下是一些流行的选项:
Fluentd:开源数据收集器,可通过插件系统轻松扩展,常与Kubernetes一起使用。
Logstash:Elastic Stack的一部分,提供强大的日志解析和转换功能。
Filebeat:轻量级的日志收集器,特别适用于收集日志文件并将数据发送到Elasticsearch或Logstash。
Fluent Bit:作为CNCF项目,是一个轻量级、多用途的日志处理器和转发器。
Heapster:早期用于Kubernetes集群的监控,虽然现在被Metrics Server取代,但仍然可以用于日志收集。
架构示例
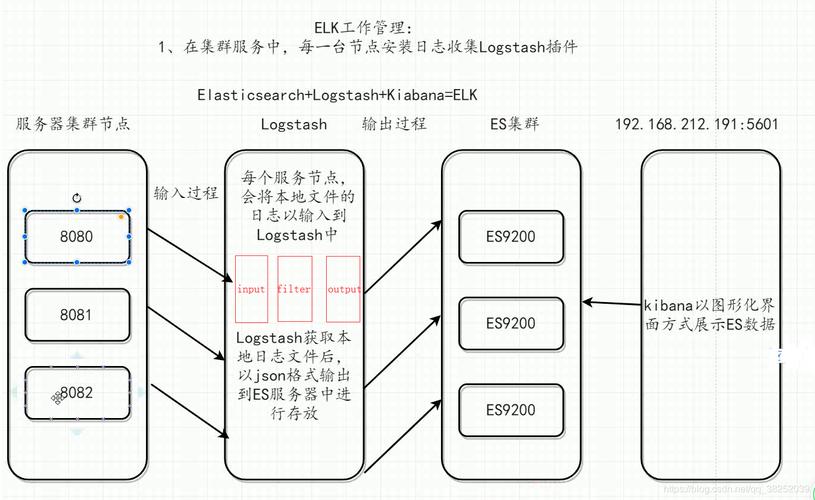
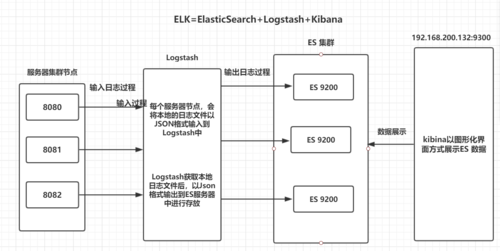
一个典型的分布式日志收集架构可能包括以下组件:
日志源:生成日志的应用或服务。
代理/收集器:例如Fluentd或Filebeat,负责从源收集日志并发送到中央系统。
消息队列:例如Kafka或RabbitMQ,用于缓冲和传输日志数据。
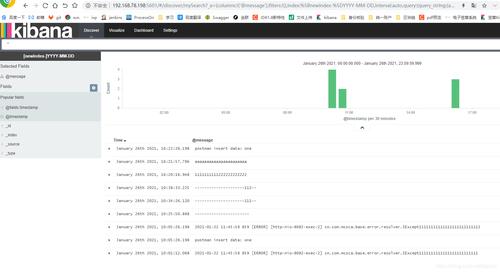
日志存储/处理系统:例如Elasticsearch,存储日志并提供搜索和分析功能。
可视化和告警系统:例如Kibana,用于展示日志数据并设置告警。
表格:常见分布式日志收集工具对比
| 工具 | 语言 | 特点 | 社区活跃度 | 适用场景 |
| Fluentd | Ruby | 灵活的插件系统,适合多种数据源 | 高 | 大规模分布式系统 |
| Logstash | JRuby | 强大的数据处理能力,与Elastic Stack集成良好 | 高 | 复杂的日志处理和分析需求 |
| Filebeat | Go | 轻量级,易于配置,专注于文件日志 | 中 | 容器和微服务环境 |
| Fluent Bit | C/JavaScript | 轻量级,支持inmemory processing,适合资源受限的环境 | 中 | 容器、IoT和资源受限环境 |
| Heapster | Go | 已不再维护,曾是Kubernetes的监控解决方案 | 低 | 遗留系统,不推荐新项目使用 |
问题与解答
Q1: 分布式日志收集系统如何处理跨地域的数据同步问题?
A1: 跨地域的数据同步可以通过多种方式实现,比如使用跨区域复制功能的存储系统,或者利用专为地理分布式设计的数据传输工具,Amazon S3的跨区域复制功能可以将数据从一个S3桶自动、异步(近实时)复制到不同区域的另一个S3桶,使用像Apache Kafka这样的分布式消息系统也可以实现跨数据中心的消息传递。
Q2: 如何确保分布式日志收集系统中的数据安全性?
A2: 数据安全性可以通过多种措施保障,包括但不限于:使用TLS/SSL协议加密数据传输过程;实施严格的访问控制和身份验证机制;对存储的日志数据进行加密;定期审计和监控日志收集系统的安全状况;以及遵循最小权限原则限制对日志数据的访问,还可以利用专用的安全信息和事件管理(SIEM)系统来检测潜在的安全威胁和异常行为。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复