
在当前互联网时代,网络数据爬取已成为获取信息的重要手段之一,无论是商业分析、市场调研还是学术研究,爬虫技术都扮演着不可或缺的角色,随之而来的是网站对于自身数据的保护需求增强,因而采取了一系列反爬虫措施来防御恶意的网络爬虫攻击,配置有效的网站反爬虫防护规则是保护网站数据安全的关键一环,具体分析如下:
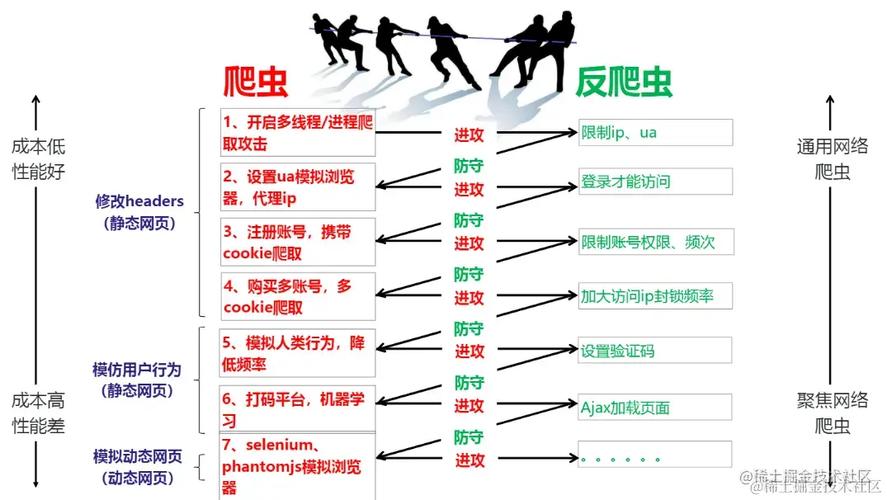

1、了解反爬虫策略
反爬虫的重要性:在互联网环境中,恶意爬虫的攻击行为可能对网站的正常运营造成严重影响,如数据被抓取、服务器负载增加等,设置有效的防护措施至关重要。
反爬虫策略的作用:通过配置反爬虫规则,可以有效识别并阻止恶意爬虫的访问,同时保障正常用户的访问不受影响。
2、设置用户行为分析
拦截与记录:在“特征反爬虫”页签中,开启合适的防护功能,选择“拦截”或“仅记录”,前者会在发现攻击行为后立即阻断并记录,后者则仅记录不阻断攻击。
自定义JS脚本:通过自定义JS脚本,加强反爬虫防护规则的灵活性和针对性,以适应特定业务场景的需求。
3、利用Bot管理报告
统计分析:F5的Bot月度统计报告提供了不同行业撞库攻击及其他恶意自动化情况的数据分析,有助于企业了解反爬虫策略的有效性和调整方向。
攻防之战:主动了解和分析爬虫行为,根据Bot报告中的数据调整反爬虫策略,保持防护措施的时效性和前瞻性。
4、使用特征反爬虫
业务场景适配:根据企业的特定业务场景,选择合适的防护功能,确保既能有效防止恶意攻击,又不会对正常用户造成干扰。
防护动作选择:明确“拦截”和“仅记录”两种防护动作的适用条件和后果,灵活运用以达到最佳防护效果。
5、开启拦截日志功能
详细记录:记录每个访问请求的详细信息,包括IP地址、访问时间、访问路径等,为后续分析提供数据支持。
行为分析:通过分析访问日志,识别出异常访问模式和可能的恶意爬虫行为,及时采取应对措施。
6、限制访问频率

设置阈值:对单一IP的访问次数进行限制,超过设定阈值则视为可疑爬虫行为,采取相应的防护动作。
动态调整:根据实际业务需求和用户访问情况,动态调整访问频率的限制值,平衡用户体验和安全防护。
7、监控用户行为
实时监控:监控用户的行为模式,识别非人类行为的访问,如访问速度异常快、访问路径随机无序等。
行为分析工具:利用专业的用户行为分析工具,提高识别精准度,减少误判和漏判。
8、保护重要信息
加密敏感数据:对敏感信息如用户数据、交易信息等进行加密处理,即使被爬取也难以解析使用。
隐藏真实路径:通过动态加载、路径混淆等技术手段,隐藏真实的数据路径,增加爬虫的难度。
在实施上述反爬虫防护措施的同时,还应注意以下几点以增强整体的防护效果:
持续更新:定期更新反爬虫策略和规则,应对爬虫技术的升级和新出现的爬虫手段。
备份与恢复:建立访问日志和重要数据的备份机制,一旦系统遭受攻击,能快速恢复服务。
用户教育:提高用户对于安全的意识,避免用户无意中成为恶意爬虫的工具或帮凶。
配置有效的网站反爬虫防护规则是保护网站数据安全、维护网站正常运行的重要手段,通过了解反爬虫的重要性,设置用户行为分析,利用Bot管理报告,使用特征反爬虫,开启拦截日志功能,限制访问频率,监控用户行为,保护重要信息等方法,可以构建起一套有效的反爬虫防护体系,随着爬虫技术的不断进步,网站管理者需要持续关注最新的反爬虫技术和策略,不断调整和优化防护措施,以应对不断变化的安全威胁。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复