
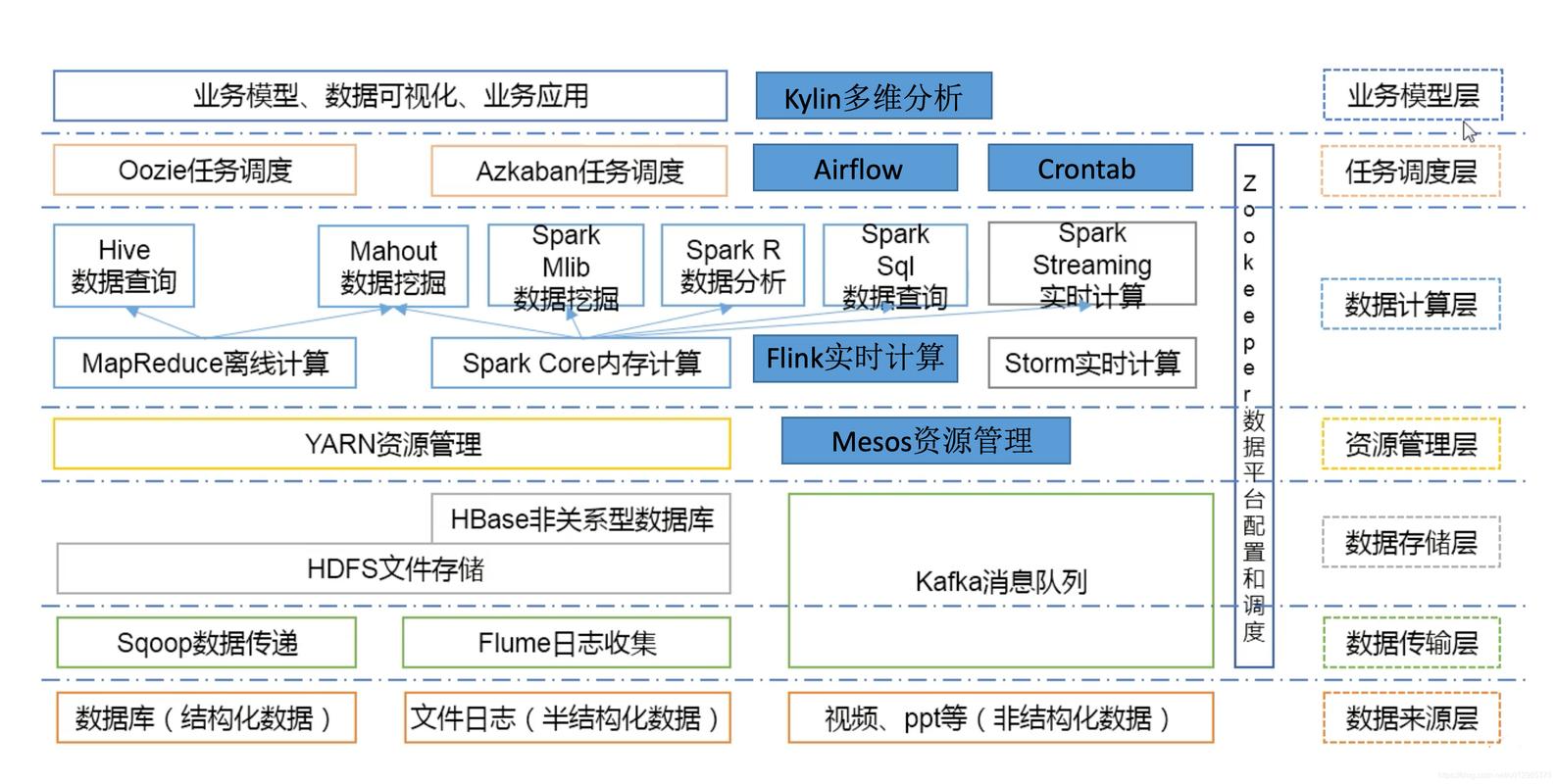
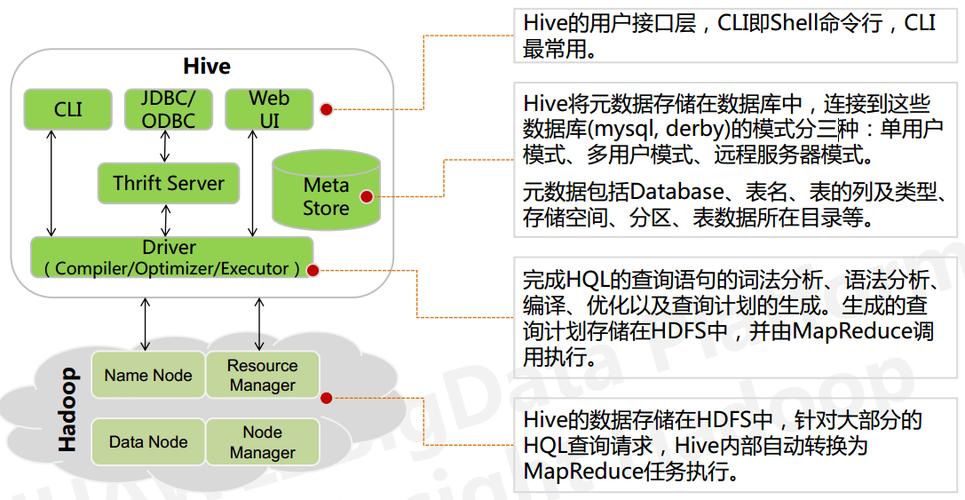
Hadoop SQL(也称为Hive)是一个基于Hadoop的数据仓库工具,它允许用户使用类似于SQL的查询语言来处理存储在Hadoop分布式文件系统(HDFS)上的大型数据集,Hive提供了一种抽象层,使得开发人员可以使用熟悉的SQL语法来查询和分析数据,而无需编写复杂的MapReduce程序。
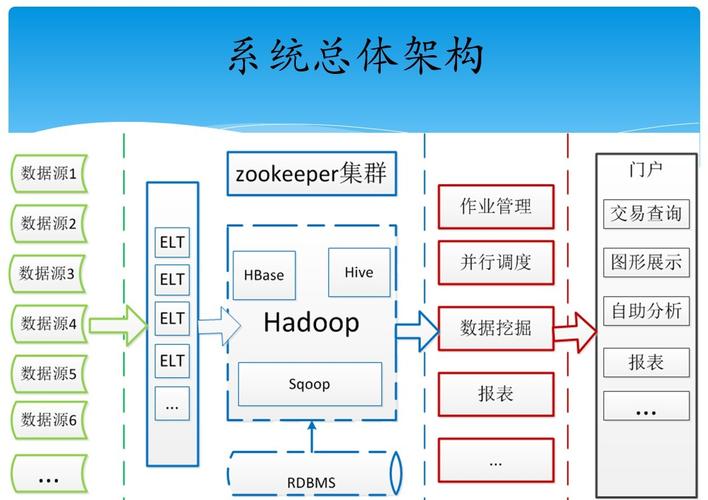

以下是一些关于Hadoop SQL(Hive)的基本概念和使用方法:
1、安装和配置:要使用Hive,首先需要在Hadoop集群上安装和配置Hive,这包括下载Hive软件包,解压并配置环境变量,以及设置Hive配置文件(如hivesite.xml)。
2、HiveQL:Hive使用自己的查询语言,称为HiveQL,它是SQL的一个子集,虽然HiveQL不支持所有SQL功能,但它支持大多数常见的SQL操作,如SELECT、INSERT、UPDATE、DELETE等。
3、创建表:要在Hive中存储数据,需要创建一个表,创建一个名为employees的表,包含id、name和salary三个字段:
CREATE TABLE employees ( id INT, name STRING, salary FLOAT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY 't' STORED AS TEXTFILE;
4、加载数据:将数据加载到Hive表中,从本地文件系统中的employees.txt文件中加载数据:
LOAD DATA LOCAL INPATH '/path/to/employees.txt' INTO TABLE employees;
5、查询数据:使用HiveQL查询数据,查询工资大于5000的员工信息:
SELECT * FROM employees WHERE salary > 5000;
6、优化性能:为了提高查询性能,可以对表进行分区和索引,按工资范围对employees表进行分区:
CREATE TABLE employees_partitioned ( id INT, name STRING, salary FLOAT ) PARTITIONED BY (salary_range STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY 't' STORED AS TEXTFILE;
将数据插入到相应的分区中:
INSERT INTO employees_partitioned PARTITION (salary_range='low') SELECT * FROM employees WHERE salary < 5000; INSERT INTO employees_partitioned PARTITION (salary_range='high') SELECT * FROM employees WHERE salary >= 5000;
7、高级功能:Hive还提供了许多高级功能,如UDF(用户自定义函数)、窗口函数、聚合函数等,以支持更复杂的数据分析任务。
Hadoop SQL(Hive)是一个强大的工具,可以帮助用户轻松地处理和分析存储在Hadoop集群上的大规模数据集,通过熟悉HiveQL和相关优化技术,用户可以充分利用Hadoop的强大功能来实现高效的数据处理和分析。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复