
分布式Redis查询 & 分布式缓存(Redis)

分布式Redis查询
基本概念与原理
1、Redis集群(Cluster)
定义:从Redis 3.0开始,官方推出了Redis Cluster作为其分布式解决方案。
功能:实现不同节点存放不同数据,并高效路由用户请求到正确的Redis节点。
2、数据分布
方式:采用散列槽(hash slots)的概念,将数据均匀分布在多个节点上。
优点:提高存储容量并实现数据的高可用性。
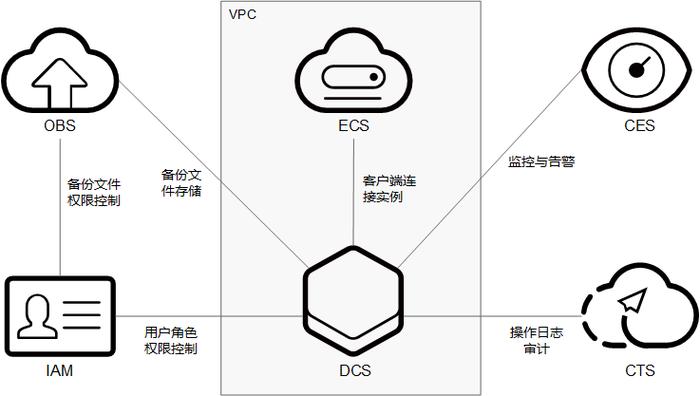
3、请求路由
过程:客户端首先连接到任意节点,如果该节点不负责所需数据,则提供转向指令至正确的节点。
优化:减少跨节点的请求转发,确保请求处理速度。
4、故障恢复
机制:通过复制(replication)和投票(vote)机制保证当节点出现故障时的数据恢复和集群稳定性。
优点:保证服务不间断,提高系统整体的可靠性。
5、性能考量
读写分离:在读多写少的场景下,通过主从复制实现读写分离,提高系统性能。

负载均衡:通过合理配置散列槽和节点数量,平衡各节点负载,避免单个节点过载。
高级应用与优化策略
1、分布式锁
命令:使用SETNX命令实现分布式锁,确保当key不存在时设置值,存在时不进行操作。
场景:用于协调多个进程或线程对共享资源的访问,防止数据竞争。
2、事务处理
命令:MULTI、EXEC等命令用于实现事务性的操作序列。
作用:保证一系列操作的原子性执行,适用于需要同步多个操作的场景。
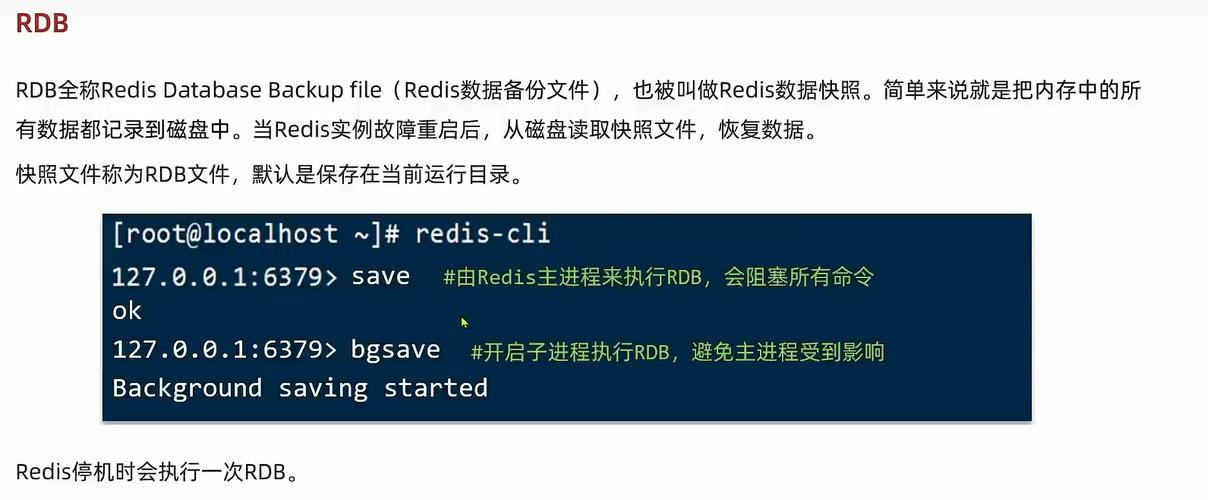
3、持久化策略
选项:RDB快照和AOF日志记录是Redis提供的两种持久化方式。
选择:根据数据安全性和性能需求选择合适的持久化策略。
4、热点处理
问题:某些高频访问的key可能导致集中的节点负载过高。
解决:通过热点数据分散或使用专门的缓存层来平衡访问压力。
5、资源隔离
措施:为不同的应用或业务分配独立的Redis实例或集群。
目的:避免相互影响,降低系统整体风险。
分布式缓存(Redis)
概念与特性
1、定义
功能:分布式缓存是以提升数据读取速度和减轻数据库负担为目的的临时数据存储方案。
角色:在分布式系统中充当快速访问层,提高响应速度和系统可伸缩性。
2、工作机制
存储:将常用数据存储在内存中,以键值对的形式提供快速读写。
同步:定期或按需与后端数据库同步,确保数据的一致性。
3、应用场景
适用:高并发访问、实时性要求高的Web应用和服务接口。
效果:显著降低数据库负担,提升用户体验。
技术挑战与解决方案
1、缓存一致性
问题:分布式环境下,确保缓存数据与数据库数据的一致性是挑战之一。
策略:采用读写分离、时间戳、版本号等方式实现数据同步。
2、缓存失效策略
方法:通过设置合理的过期时间、使用LRU(Least Recently Used)算法等驱逐旧数据。
目的:保证缓存空间的有效利用,避免因缓存过时数据而造成的数据不一致。
3、缓存穿透与雪崩
描述:缓存穿透指查询不存在的数据,雪崩指缓存在同一时间大面积失效。
对策:采用布隆过滤器、备份缓存层等技术手段解决这些问题。
4、热key处理
问题:对于高访问量的热key,单点故障风险增大。
应对:通过多级缓存结构或热key动态迁移平衡负载。
5、高可用性
需求:确保缓存服务的持续可用性,特别是在节点故障情况下。
实施:通过主备复制、故障转移等技术保障服务连续性。
无论是分布式Redis查询还是分布式缓存,都面临着诸多技术挑战和性能优化的需求,通过合理设计和运用各种策略与工具,可以有效提升系统的性能和稳定性,在构建分布式系统时,应充分考虑这些因素,以确保系统的高效运行和良好的扩展性。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复