
在当今的计算环境中,分布式系统已经成为处理大规模数据和高并发请求的标准配置,在这种架构下,缓存技术尤其是分布式缓存扮演着至关重要的角色,它能够显著提升数据访问速度,减少数据库的压力,Redis作为一种高效的内存数据存储系统,广泛应用于分布式缓存解决方案中,本文将深入探讨Redis在分布式缓存中的应用,分析其同步机制,并提出相关的实践建议和潜在问题。

理解分布式缓存的基本概念是重要的,分布式缓存是将缓存数据分布存储在多台服务器上的缓存系统,它通过将热点数据保存在内存中,从而快速响应用户的请求,避免每次都要去访问数据库,这样能大幅度提高应用的性能和可伸缩性。
在分布式缓存的实现上,Redis提供了几种主要的方式:
1、主从复制:这是最常见的分布式策略之一,通过将数据从主节点复制到多个从节点,可以减轻主节点的压力,并提供数据的副本以支持更多的读操作。
2、哨兵模式:Redis Sentinel用于监控主节点的状态,当主节点出现故障时,自动进行故障转移,选择一个从节点升级为新的主节点。
3、集群模式:Redis Cluster通过将数据分散在多个节点上,每个节点负责一部分数据的方式来实现,这不仅可以提升数据存储的容量,还能提高并发处理能力,每个节点都保存了其他节点的信息,使得客户端可以连接到任意一个节点操作整个数据库。
在实际应用中,使用Spring Boot结合Redis来实现分布式缓存是一种常见的模式,这种模式允许开发者通过简单的配置就能启用缓存功能,而不需要关心底层的缓存同步和数据一致性问题,Spring Cache与Redis的结合提供了一个方便的抽象层,使得缓存逻辑与业务逻辑得以分离,极大地提高了开发效率和系统的可维护性。
分布式缓存并非没有挑战,数据一致性问题、缓存穿透和雪崩、以及高可用性等问题都是设计和实现分布式缓存系统时需要面对的重要问题,缓存数据与数据库数据可能不同步,导致用户读取到过期或不正确的数据,大量的并发请求可能导致缓存系统过载或崩溃,即所谓的缓存雪崩。
解决这些问题的方法包括:
增加缓存逐出策略:合理设置缓存失效时间,并使用如LRU(最近最少使用)等算法来逐出旧数据。
备份和故障转移:设计良好的备份策略和故障转移机制,确保一旦某个节点失败,系统可以迅速恢复。
数据分片和负载均衡:通过数据分片将数据均匀分布在多个节点上,使用负载均衡技术保证请求平均分配到各个节点,避免单点过载。
归纳一下,Redis作为一个强大的分布式缓存解决方案,不仅提供了高效的数据存取功能,还支持复杂的数据结构和高可用性配置,通过合理的架构设计和配置优化,可以最大化地发挥Redis在分布式系统中的作用,提升整体性能和稳定性。
问题与解答:
Q1: 如何确保Redis分布式缓存的数据一致性?
A1: 确保数据一致性可以通过几种方式实现,例如使用Redis的事务功能来保证一系列操作的原子性,或者采用TTL(生存时间)和TTI(空闲时间)策略来控制数据的有效期,同时配合使用主从复制和哨兵模式来保证故障恢复后的数据同步。
Q2: 在Redis分布式缓存中如何处理缓存雪崩现象?
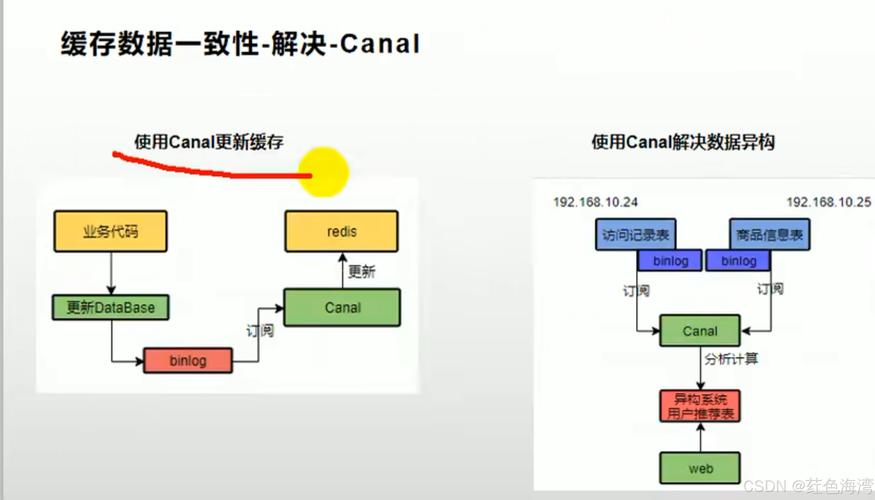
A2: 处理缓存雪崩的策略包括设置不同的过期时间以避免大量缓存同时失效,使用限流措施来防止缓存被过量请求击穿,以及部署额外的备份缓存节点来分担请求压力,实现服务的熔断和降级也是有效的策略,可以在缓存服务不可用时保持系统的部分运行。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复