
分布式数据系统是一种将数据分散存储在多个物理位置的系统,旨在提高数据的可访问性、可靠性和扩展性。通过在不同地点的数据节点上存储数据副本,系统能够在节点故障时保持服务的连续性,同时支持大规模的数据处理和分析。
分布式数据系统的数据分布式存储是一种在多个计算机或服务器上存储数据的技术,旨在实现高可靠性、可扩展性和性能。

(图片来源网络,侵删)
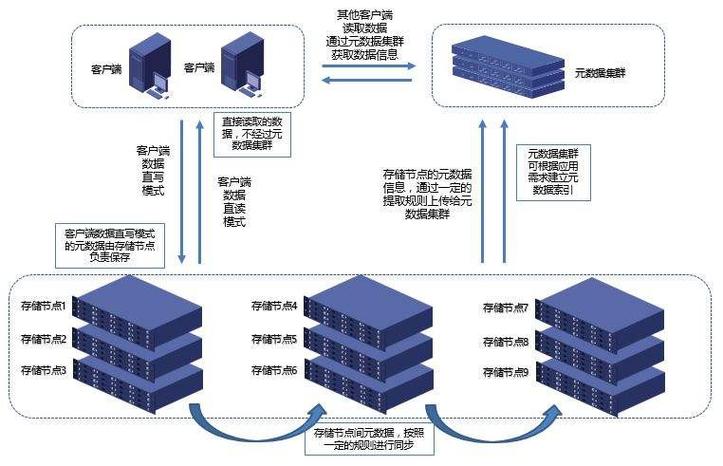
分布式数据存储涉及将数据分散存储在通过网络连接的多个存储节点上,这种存储方式利用了多台机器的存储资源,通过特定的规则和协议,协同工作以提供统一的数据存储和访问服务,它的核心在于如何有效地管理分布在不同硬件资源上的数据,并确保数据的完整性与可用性。
分布式存储的主要目的是提高数据的可用性、可靠性和性能,将数据分散到不同的节点上,即使部分节点发生故障,系统仍能从其他节点恢复数据,保障数据的安全,分布式存储可以按需动态扩展存储容量,通过增加更多的节点来提升整体系统的性能与存储能力。
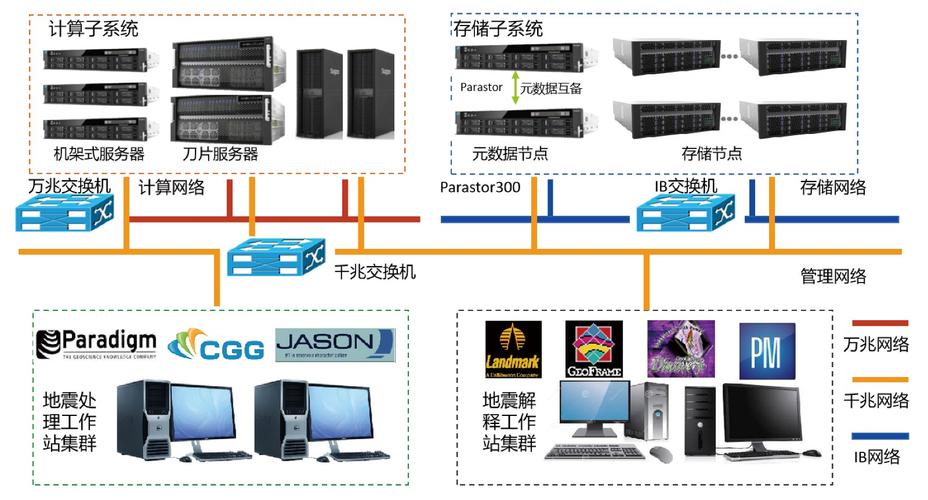
分布式存储系统通常包含有多个组成部分,如腾讯云的对象存储服务,它没有容量上限,支持海量数据存储,适用于大数据计算与分析等场景,Ceph的RADOS系统提供了可靠的、智能的、分布式的特性,实现了高性能和高自动化的存储功能。
分布式数据存储系统设计时需要考虑数据的分片和复制策略,分片是将数据按照一定的规则切割成小块,然后分别存储到不同的节点上,而复制则是将数据在不同节点上保留多份拷贝,以确保数据可靠,Google的GFS(Google文件系统)就是通过采用分布式集群来解决如何存储海量数据以及保证数据安全的问题,Hadoop的HDFS(Hadoop分布式文件系统)也是根据类似原理实现的,具有高容错性和高吞吐量的特点,非常适合于处理大规模数据集。
分布式数据存储是现代计算机科学领域中的一项核心技术,用于满足日益增长的数据处理需求,通过将数据分布式地存储和管理,系统能够提供更高的性能、更好的可靠性和无限的扩展性。
(图片来源网络,侵删)
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复