
FP树,即频繁模式树,是FPgrowth算法的核心数据结构,用于在机器学习和数据挖掘中高效地挖掘频繁项集,FPgrowth算法的优点在于其能够压缩存储数据,并且通过构建FP树来快速访问和处理数据,从而提高算法的效率和准确性,下面将详细探讨FP树的构建过程,包括FP树的数据结构特点,以及如何从零开始构建一个FP树:

1、FP树的表示方式
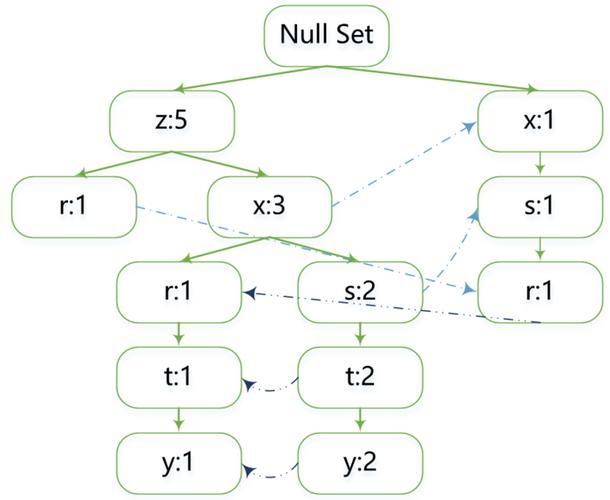
数据结构特点:FP树是一种树形结构,它能够有效地存储频繁项集信息,每个节点代表一个元素项,并记录该元素项的出现频率,树的路径表示的是数据集中的一个事务,路径上每个节点的出现次数反映了该元素项在数据集中的频繁程度。
相似元素的连接:在FP树中,具有相似元素的集合会共享树的一部分,只有当集合之间完全不同时,树才会分叉,这种设计使得FP树能够以更紧凑的形式存储重复的元素项,减少了树的大小,提高了存储和检索效率。
2、FP树的构建过程
统计元素频率:需要扫描原始事务集,统计各个元素项出现的频率,这一步是为了确定哪些元素项是频繁的,并需要被包含在FP树中。
支持度过滤:根据预先设定的支持度阈值,过滤掉那些不满足最小支持度要求的元素项,这样做可以去除噪声数据,只保留对分析有价值的信息。
元素排序:按照元素项的频率降序排列,这是因为FP树是按照元素项的频率构建的,频率高的元素项会被放在树的更上层,这样可以减少树的深度,提高后续挖掘操作的效率。
实际构建:依据排序后的元素项列表构建FP树,从根节点开始,按照元素项的顺序逐个添加子节点,如果子节点已存在,则增加其计数器,对于每个事务,都会从根开始找到相应的路径,并在路径末端添加新的节点或者增加现有节点的计数器值。
3、与Apriori算法的比较
减少数据库扫描次数:FPgrowth算法的一个显著优点是它只需要在构建FP树时扫描数据库两次,而传统的Apriori算法需要多次扫描数据库,这大大减少了I/O开销。
处理大规模数据:由于FP树是在内存中构建的,它能够处理大规模数据,相比之下,Apriori算法在处理大数据集时可能会遇到性能瓶颈。
4、实验和应用
创建FP树:通过简单的数据示例,可以手动构建FP树,加深对其构建过程的理解。
挖掘频繁项集:从构建好的FP树中挖掘频繁项集,这是FPgrowth算法的主要应用之一,可以发现数据中的关联规则和模式。
FP树的构建是FPgrowth算法的核心部分,它通过一种高效的数据结构来存储和处理数据,从而在机器学习和数据挖掘中发挥着重要作用,构建FP树的过程包括统计元素频率、支持度过滤、元素排序和实际构建等步骤,与传统的Apriori算法相比,FPgrowth算法在效率和准确性上都有显著提升,通过实验和应用,可以进一步理解和掌握FP树的构建和使用。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复