
服务器自动杀进程_处置风险容器
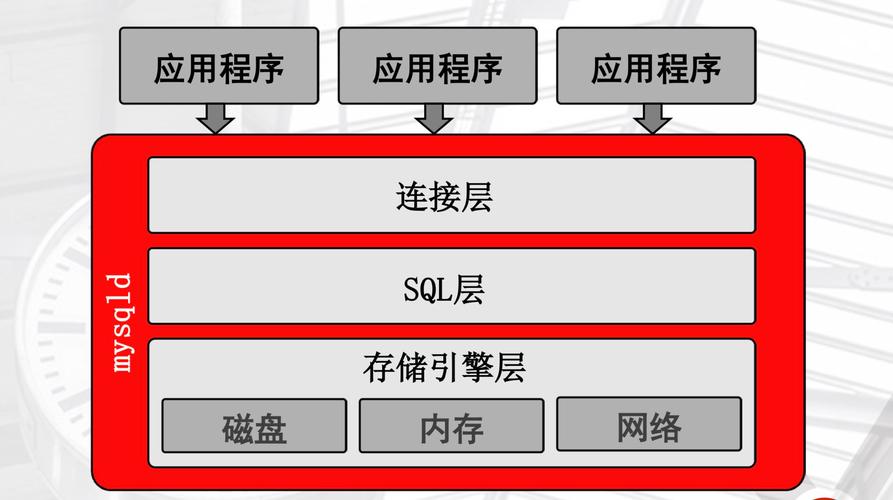

在服务器管理中,自动杀掉异常或占用资源过多的进程是一种常见的维护手段,这可以防止单个进程耗尽系统资源,导致整个系统的性能下降或崩溃,对于运行容器化应用的服务器来说,这种机制尤其重要,因为容器可能会因为配置错误、内存泄露或者恶意攻击而消耗大量资源,下面将详细探讨如何设置和管理一个能够自动处置风险容器的系统。
监控与分析
需要对服务器进行实时监控,以便及时发现问题,可以使用如下工具:
Prometheus: 开源监控系统,用于存储实时的服务运行指标数据。
Grafana: 可视化工具,配合Prometheus使用,用于展示和分析指标数据。
cAdvisor: 用于监控容器的资源使用情况和性能指标。
风险识别
通过上述工具收集的数据,我们可以定义一些风险指标,

CPU使用率持续高于90%
内存使用量超过容器限制的90%
磁盘I/O操作频繁且响应时间长
这些指标可以帮助我们识别出可能对系统稳定性构成威胁的容器。
自动处置机制
一旦识别出风险容器,我们需要一个自动化的流程来处理它们,这个流程可以包括以下步骤:
1、警告: 当容器首次达到风险指标时,发送警告通知给管理员。
2、限制: 如果容器继续消耗过多资源,可以动态调整其资源限制,比如降低CPU和内存分配。
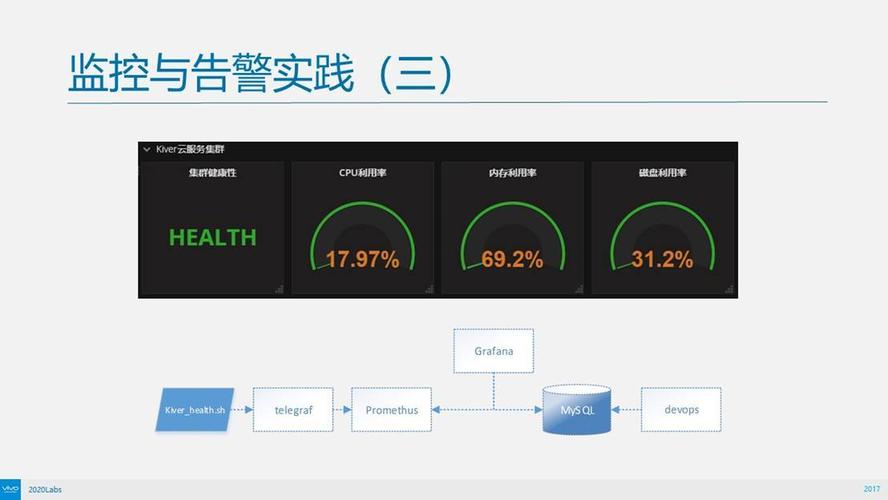
3、重启: 对于一些暂时性的问题,重启容器可能能解决问题。
4、终止: 如果上述步骤无效,作为最后的手段,终止该容器以防止它影响其他服务。
实施步骤
以下是实现这一机制的大致步骤:
1、部署监控工具: 安装并配置Prometheus、Grafana和cAdvisor。
2、设置警报规则: 在Prometheus中根据预设的风险指标设置警报规则。
3、编写处置脚本: 根据警告、限制、重启和终止的流程编写自动化脚本。
4、集成到自动化平台: 将脚本集成到自动化运维平台,如Ansible、Kubernetes operator或自定义的自动化工具。
5、测试与调优: 在实际环境中测试处置流程,并根据结果进行调整优化。
风险管理策略
在实施自动杀进程策略时,需要注意以下几点:
避免误杀: 确保风险指标准确无误,避免正常容器被误杀。
备份与恢复: 对于关键服务的容器,在终止前应确保有备份和快速恢复的方案。
灰度测试: 在全面部署之前,先在小范围内测试处置机制的有效性和安全性。
人工干预: 在自动处置流程中加入人工确认环节,以防自动化系统的错误判断。
单元表格
| 步骤 | 工具/组件 | 描述 |
| 监控部署 | Prometheus, Grafana, cAdvisor | 部署监控系统和服务以收集容器指标 |
| 警报设置 | Prometheus Alertmanager | 配置警报规则以便在达到风险指标时触发 |
| 编写脚本 | 自定义脚本 | 创建用于自动处置的脚本 |
| 集成自动化 | Ansible, Kubernetes operator | 将脚本集成到自动化运维平台 |
| 测试与调优 | 实际环境测试 | 测试流程并优化以确保准确性和效率 |
相关问题与解答
Q1: 如何处理因自动杀进程而导致的业务中断?
A1: 业务中断的风险可以通过以下几个方式来减轻:
实现高可用架构,如多副本或集群,确保服务的连续性。
在终止容器前进行健康检查和通知管理员,给予人工干预的机会。
设计快速恢复流程,比如使用预先准备好的备份来快速替换被终止的容器。
对于非关键服务,可以接受短暂的中断,并通过监控及时修复问题。
Q2: 自动杀进程是否可能导致系统的连锁反应?
A2: 是的,自动杀进程有可能导致系统的连锁反应,特别是当一个容器为多个服务提供关键功能时,为了防止这种情况,可以采取以下措施:
仔细选择哪些容器应该被自动杀进程,避免对关键服务造成影响。
在自动化脚本中加入逻辑判断,评估终止容器可能带来的影响。
实施分布式追踪,了解各个服务之间的依赖关系,以便更准确地评估风险。
增加缓冲机制,比如队列或缓存,以减少单个服务失败对整个系统的影响。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复