
在当今大数据和云计算迅猛发展的背景下,传统的关系型数据库已难以应对日益增长的数据存储和处理需求,分布式数据库凭借其可扩展性、高可用性和故障隔离等优势,成为了解决大规模数据处理的关键技术,本文将深入探讨分布式数据库的设计原则,旨在帮助读者构建高效、稳定的分布式数据库系统。
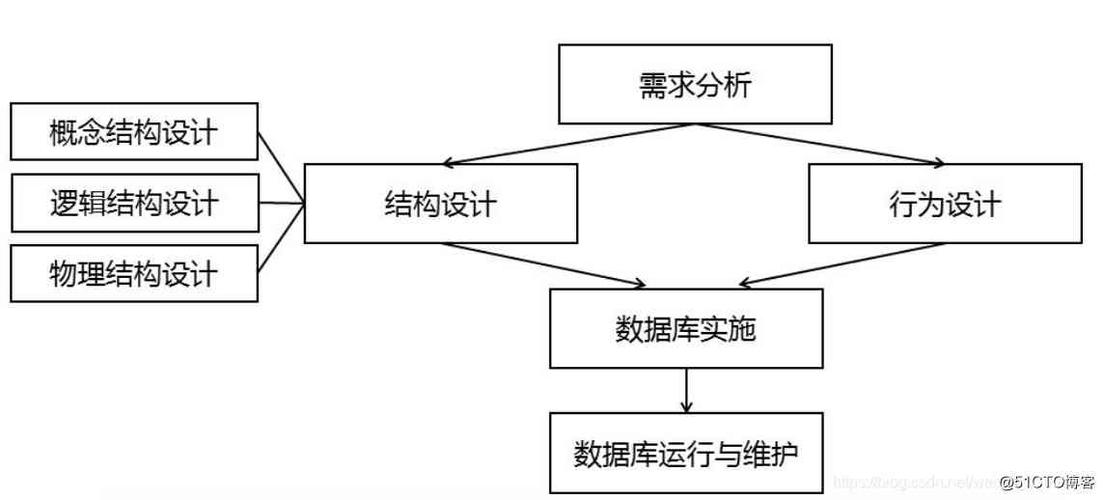

核心设计原则
1、透明性
分布式透明性:分布式数据库应隐藏其分布式特性,对用户呈现为一个逻辑上的单一数据库,这意味着,用户无需关心数据存储在哪个节点上,只需通过统一的查询语言进行操作。
性能优化:虽然分布式环境提供了高并发和负载均衡的可能,但设计时需考虑查询优化,减少跨节点通信,以保持高性能。
2、一致性与可用性
CAP原理:根据CAP原理(Consistency, Availability, Partition Tolerance),分布式数据库设计需要在一致性、可用性和分区容忍性之间做出权衡。
一致性级别选择:设计者应根据应用场景选择合适的一致性级别,如强一致性、最终一致性或因果一致性。
3、数据分片与复制
数据分片策略:数据分片是将数据分散存储在不同节点的过程,常见的分片策略有范围分片、哈希分片及目录分片。
数据复制策略:为了提高可用性和容错能力,分布式数据库通常采用数据复制技术,包括主从复制、多主复制等。
4、故障隔离与恢复
故障检测与隔离:设计应确保系统能够快速检测并隔离故障节点,避免影响整个系统的运行。
数据恢复机制:应实现有效的数据备份和恢复机制,保证在节点故障后能迅速恢复数据。
5、扩展性
水平扩展:分布式数据库应支持无缝的水平扩展,即在不中断服务的情况下增加或减少节点。
负载均衡:设计应考虑动态负载均衡机制,根据各节点的工作负载合理分配请求。
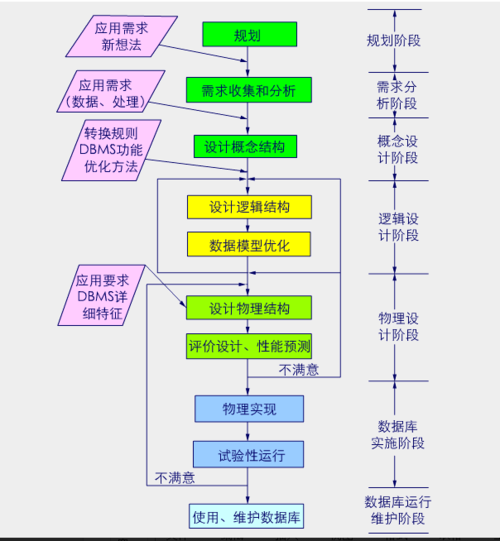
设计方法与考量
组合法与重构法:根据设计是基于现存的数据系统还是构造一个全新的数据库系统,可以采用组合法或重构法来创建分布式数据库,组合法基于现有系统,采用自底向上的方式构建;而重构法则是从零开始构建一个全新的分布式数据库系统。
拆分原则与难点:在分布式数据库设计中,如何合理地拆分数据是一个关键问题,拆分原则应考虑到数据的访问模式、业务关联度等因素,拆分过程中可能遇到的难点,如数据迁移、跨节点事务处理等,也需要设计者提前规划解决方案。
分布式数据库设计的核心在于平衡透明性、一致性、可用性、扩展性和故障处理等多个方面的需求,设计者需要根据具体的应用场景和需求,选择合适的设计原则和技术策略,以确保分布式数据库系统既能高效处理海量数据,又能提供稳定可靠的服务。
相关问答
Q1: 在设计分布式数据库时,如何选择合适的数据分片策略?
A1: 选择数据分片策略应考虑数据的访问模式、规模和更新频率,如果数据访问有明显的地域特征,可以采用范围分片;如果希望实现高效的负载均衡,哈希分片可能是更好的选择。
Q2: 如何平衡分布式数据库中的一致性和可用性?
A2: 可以通过调整数据复制策略来实现一致性和可用性之间的平衡,采用最终一致性模型可以提高系统的可用性,但可能会牺牲一定的数据一致性,设计者应根据业务需求和场景特点做出选择。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复