
多音色语音合成应用方案概述

背景介绍
随着人工智能技术的不断进步,语音合成技术也得到了快速发展,多音色语音合成技术能够根据不同的应用场景和用户需求,生成具有不同声音特征的语音,大大增强了语音合成系统的实用性和个性化体验。
技术架构
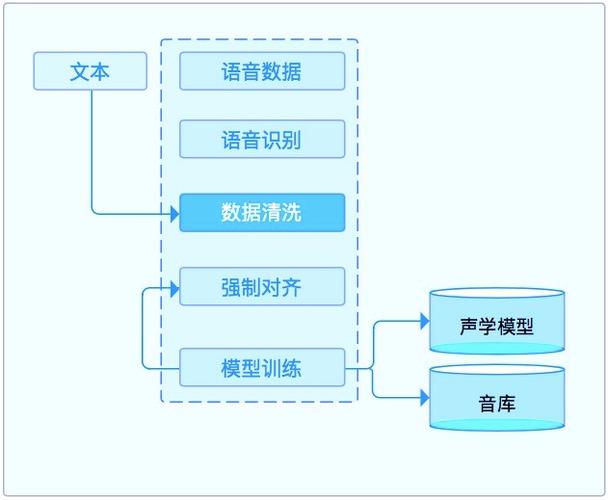
数据准备
1、声音库构建:收集多种音色的声音样本,包括不同性别、年龄段、情感状态等。
2、特征提取:对声音样本进行声学特征提取,如基频、音色、音强等。
3、标注与分割:对声音样本进行准确的时间标注和分割,以便后续处理。
模型训练
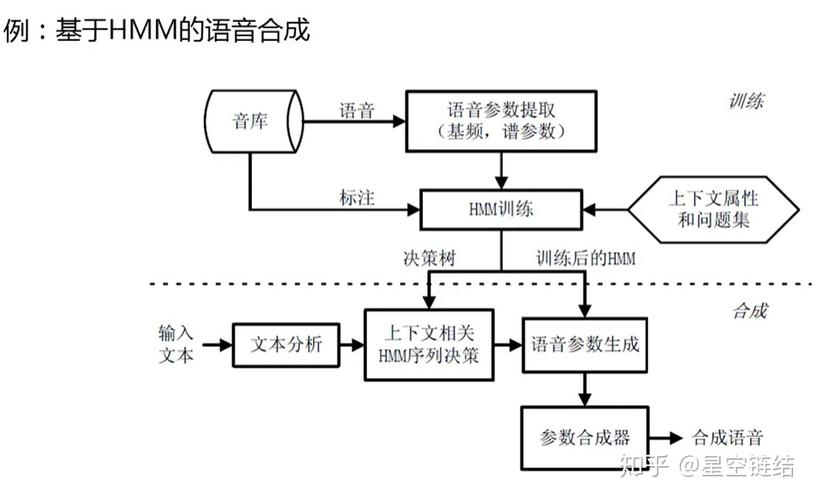
1、深度学习框架选择:采用适合语音合成的深度学习框架,如Tacotron、WaveNet等。
2、模型设计:设计能够处理多音色输入的神经网络结构。
3、训练与优化:使用大量多音色数据对模型进行训练,并进行参数优化。
1、用户界面设计:提供友好的用户界面,使用户能够轻松选择或定制所需的音色。
2、实时合成:实现高效的实时语音合成功能,确保用户体验流畅。
3、反馈机制:建立用户反馈机制,不断优化语音合成效果。
应用场景
个性化阅读:为电子书、新闻等提供不同朗读人声音的选择。
虚拟助手:使智能助手拥有更多变的声音,提升互动体验。
娱乐产业:在游戏、动画中应用不同角色的独特声音。
公共服务:如导航、提示音等可以根据用户偏好调整音色。
性能评估
自然度:评估合成语音的自然流畅程度。
相似度:评估合成语音与目标音色的相似性。
可懂度:确保合成语音的清晰度和理解度。
稳定性:系统的稳定性和在不同环境下的表现。
相关问题与解答
Q1: 多音色语音合成技术是否会侵犯声音所有者的版权?
A1: 多音色语音合成技术在开发过程中,应确保所有使用的声音样本均已获得合法授权,或者使用公开的无版权声音库,合成的语音应当避免与特定个人的声音过于相似,以免引发版权或肖像权争议。
Q2: 如何保证多音色语音合成的音质?
A2: 保证音质的关键在于高质量的数据准备、先进的模型设计和充分的模型训练,需要采集高清晰度、多样性的声音样本;选用适合语音合成任务的深度学习模型并对其进行定制化设计;通过大量的训练数据和细致的调优工作来优化模型性能,确保最终合成语音的音质。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复