
多级索引算法主要涉及的是如何构造和管理这个索引以实现高效的数据检索,以下是对多级索引算法的详细解析:

(图片来源网络,侵删)
1、基础概念
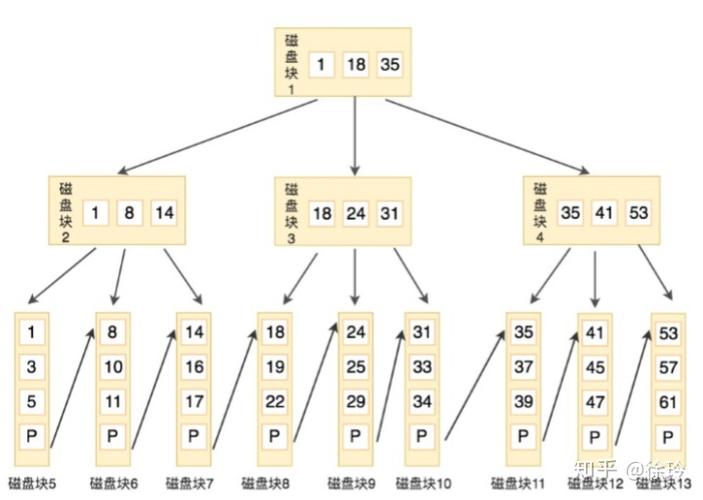
多级索引(MultiIndex)是标准索引对象的分层模拟,在Pandas库中被广泛应用,这种结构允许你在一个轴上储存并操作多层次的标签,你可以把多级索引看作是一个元组数组,其中每个元组都是惟一的。
2、创建方法
多级索引可以通过多种方式创建,包括从数组列表、元组数组、交叉迭代器集或直接从一个DataFrame创建,不同的创建方法适应不同的数据结构和需求,提供了灵活性来适应复杂的数据建模场景。
3、操作应用
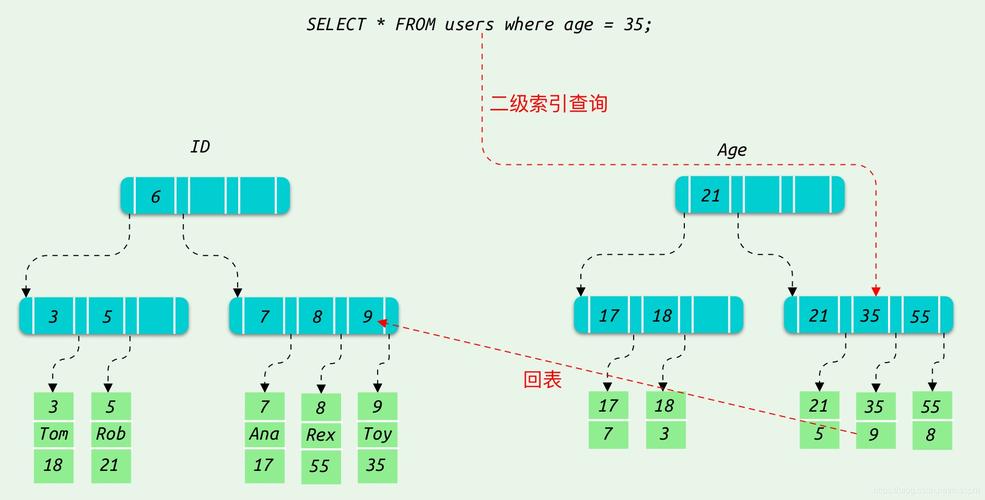
多级索引的操作通常通过各种标函操作进行,如iloc基于位置的索引操作,对于单级索引,首先会尝试按标签选择,如果标签不存在,则按位置选择,而对于多级索引,选择则完全基于标签进行。
4、性能优势
并行计算:多级索引的结构可以很好地利用计算机硬件资源的并行工作特性,例如多CPU、磁盘阵列等,从而显著提高数据处理的效率。
(图片来源网络,侵删)
灵活性:多级索引由于其层次结构的特性,为处理和分析复杂的数据提供了极大的灵活性,尤其是对于高维数据的处理更是如此。
5、应用场景
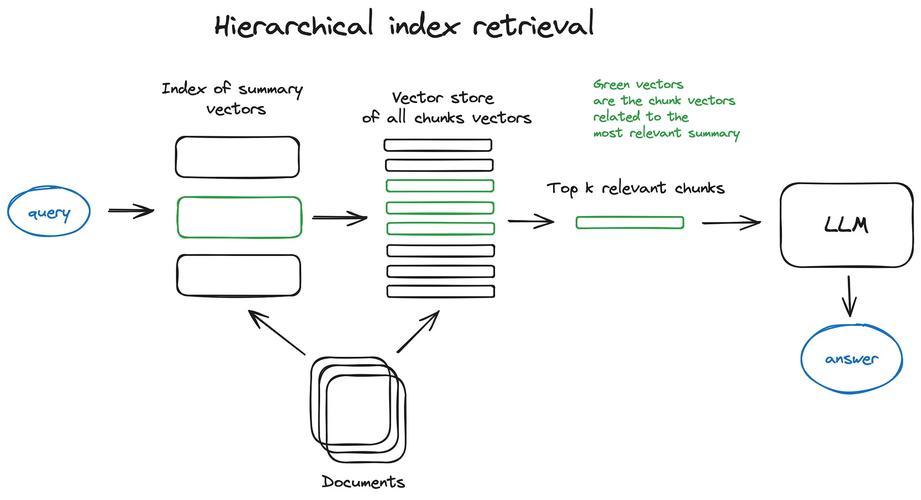
多级索引广泛应用于需要高效检索超大型数据量的GIS系统、复杂的数据分析任务以及任何需要快速精确访问大量信息的场景,它通过将多个不同或相同的索引方法组合使用,对单级索引空间或范围进行多级划分,以解决这些应用中的效率问题。
多级索引算法是一种强大的数据结构工具,用于管理和检索具有复杂结构的数据,通过适当的构建与维护,多级索引可以极大地提高数据处理任务的效率和准确性,特别是在处理和分析具有高维度和大规模数据集时。
(图片来源网络,侵删)
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复