
大数据组件对接概览
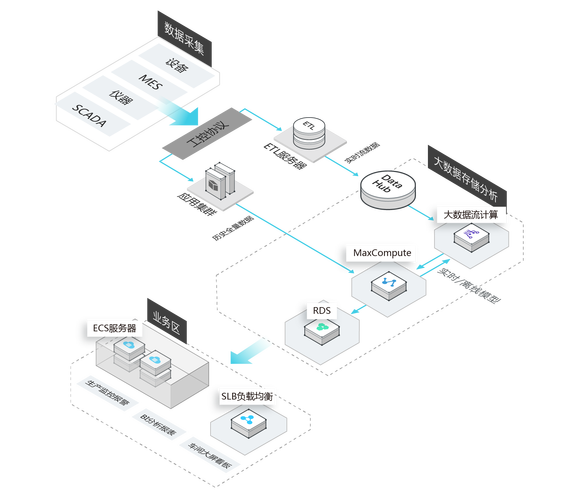

在现代企业中,大数据技术的应用越来越广泛,为了有效地处理和分析海量数据,不同的大数据组件需要相互对接和协同工作,以下是一些常见的大数据组件及其对接的基本概念。
数据存储组件
hadoop distributed file system (hdfs): 作为大数据的存储基础,hdfs能够在多个物理服务器上存储大规模数据集。
nosql数据库: 如cassandra、hbase等,它们提供了对海量数据的高性能读写能力。
数据处理组件
apache hadoop mapreduce: 用于大规模数据集的并行处理。
apache spark: 提供比mapreduce更快的数据处理框架,支持实时数据处理和机器学习算法。
数据管理组件
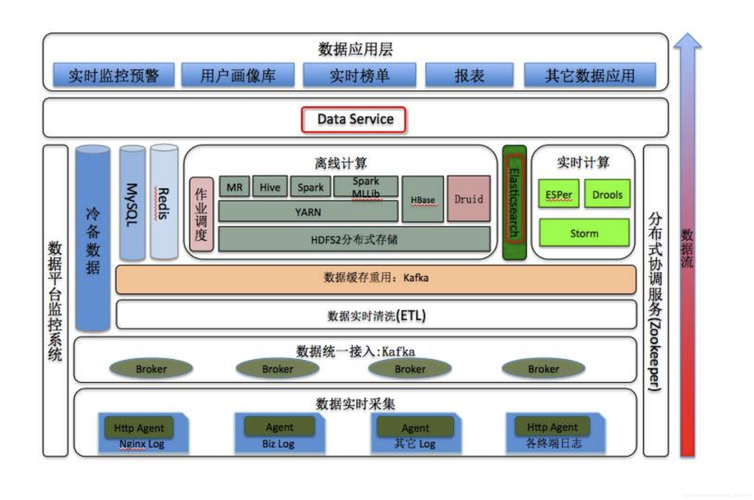
apache hive: 将sql查询转换为mapreduce任务,使用户能通过sql语言查询数据。
apache pig: 高级平台,允许使用pig latin语言编写数据转换和处理脚本。
数据搜索与索引组件
apache solr: 基于lucene的搜索平台,为大数据环境提供全文搜索功能。
elasticsearch: 基于lucene的搜索引擎,提供分布式、多租户能力的全文搜索引擎。
数据集成与etl组件
apache nifi: 一个易于使用、功能强大且可靠的系统,用于处理和分发数据。
apache kafka: 高吞吐量的分布式发布订阅消息系统,通常用于日志数据的处理。
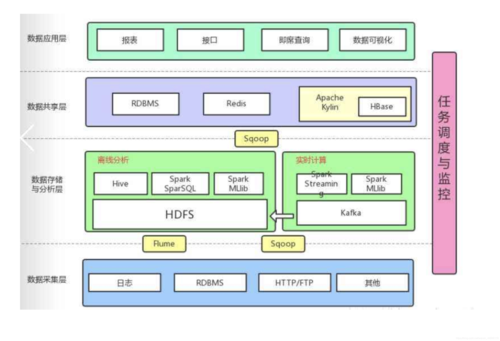
数据可视化组件
kibana: 配合elasticsearch使用的数据可视化插件。
tableau: 一款商业智能工具,可以连接多种数据源进行复杂的数据分析和图表展示。
对接流程与注意事项
对接流程
1、需求评估:明确业务需求,确定需要对接的组件。
2、技术选型:根据需求选择合适的大数据组件。
3、环境搭建:配置所需的硬件资源和软件环境。
4、接口对接:编写代码或使用现成的适配器来连接不同组件。
5、数据流设计:设计合理的数据流动路径,确保数据能够高效地在不同组件间流转。
6、测试验证:进行全面的测试,包括单元测试、集成测试和性能测试。
7、部署上线:将经过充分测试的系统部署到生产环境。
8、监控维护:监控系统运行状态,及时调整和优化。
注意事项
确保所有组件的版本兼容,避免因版本差异导致的兼容性问题。
考虑数据的安全性和隐私保护,特别是在数据传输和存储过程中。
关注系统的性能和扩展性,确保在数据量增长时依然能够保持良好的性能。
实施有效的错误处理和异常管理策略,保证系统的鲁棒性。
准备充分的文档和操作手册,方便后续的维护和升级工作。
相关问题与解答
q1: 如何确保不同大数据组件之间的数据一致性?
a1: 确保数据一致性需要采取以下措施:
使用事务支持的数据存储系统,如acid兼容的nosql数据库。
实现幂等操作,确保重复的操作不会改变系统状态。
利用数据校验和修复机制,定期检查数据完整性并修复不一致。
采用分布式事务管理器,比如apache kafka,来协调跨系统的数据流。
q2: 在对接大数据组件时遇到性能瓶颈应该如何解决?
a2: 面对性能瓶颈,可以采取以下步骤来解决:
进行性能剖析,定位瓶颈所在(如cpu、内存、磁盘i/o或网络)。
根据瓶颈类型优化配置参数,比如增加内存分配、调整jvm设置等。
考虑引入更多的计算资源,如增加节点、扩展集群规模。
优化数据流设计,减少数据传输量,合理分配负载。
如果可能,升级到更高版本的组件以获取性能提升和新特性。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复